



あなたはRubyのコードを書いていて、冗長だと感じることはありませんか?
Rubyにはたくさんの便利なメソッドがあります。
うまく使いこなすことで、記述量を減らし、見通しの良いコードを書けるようになるでしょう
記述量を減らすことによって、開発時間を短縮し、バグを減らすことも可能です。
そこで今回は便利なRubyのmapメソッドについてご紹介します。
mapメソッドには
・様々な場面で使えて汎用性が高い。
・記述量を大幅に減らしてくれる。
というメリットがあります。
この記事では、mapメソッドの基本的な使い方から、開発の現場でも使える応用的な使い方まで、解説していきます。
これを機に、mapメソッドをリファクタリングに是非活用してみてください。
リファクタリングとは、ソースコードの実行結果を変えずに、安全性を高めることです。
この記事の目次

mapメソッドの基本
mapメソッドはEnumerableモジュールに実装されたメソッドです。
Enumerableモジュールとは、集合を表すクラスに数え上げや検索などのメソッドを提供するパッケージのようなものです。
mapメソッドは、このモジュールを組み込んだハッシュや配列に対して使用することができます。
この記事では主に配列に対するmapメソッドの使い方をご紹介します。
eachメソッドとの違い
例えば、配列オブジェクトのそれぞれの要素を
小文字から大文字に変換するような処理を書く場合
以下のようなコードを書いていませんか?
#eachメソッドを使用した場合 new_array = [] ["a", "b", "c"].each do |str| new_array &<< str.upcase</pre> <pre> end</pre> <pre> p new_array</pre> <pre> # =>["A", "B", "C"]
mapメソッドを使うとこのように書けます。
#mapメソッドを使用した場合 p ["a", "b", "c"].map do |str| str.upcase end # =>["A", "B", "C"]
さらにmapメソッドには省略記法があり、上記の処理を以下の記述により更に減らすことが出来ます。
#省略記法を使用した場合 ["a", "b", "c"].map(&:upcase) # =>["A", "B", "C"]
&(アンパサンド)はそのメソッドをブロックとして展開することを意味します。
このようにeachでは数行かかるコードも、mapメソッドを使うことで、処理を格段に短くすることができます。
以上がmapメソッドの基本的な使い方です。
collectメソッドとの違い
Rubyのmapメソッドとcollectメソッドは、全く同じ動作をするメソッドです。
同じ機能のメソッドに違う名前がついている理由は、「map」「collect」それぞれのメソッドの発想の違いにあります。
mapは「データ構造を保ったまま、あるルールに従って元のデータ構造を別のデータ構造に変換する」という発想です。
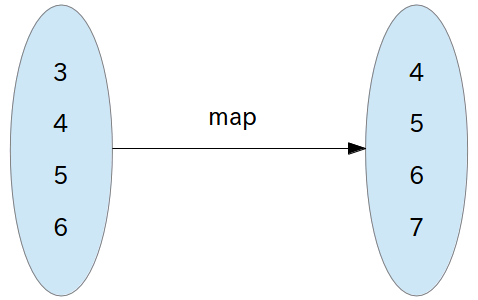
出典:Rubyist Magazine
一方、collectは「データ構造内の全ての要素に対して、ある処理を繰り返し実行し、その結果を集めたもの」という発想です。
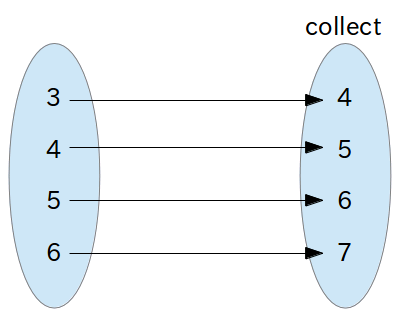
出典:Rubyist Magazine
つまり、mapとcollectは「こうした処理が必要だ」という同じ動機から、異なる発想によって実装されたメソッドなのです。
以上がmapメソッドの基本的な使い方です。
mapメソッドの応用
次にmapメソッドの応用的な使い方について紹介していきたいと思います。
Hash#mapの使い方
mapメソッドは配列に対してだけではなく、ハッシュに対しても使うことができます。
hash = {genre: "movie", title: "hurrypotter"}
hash.map{|key, value| value.upcase}
# =>["MOVIE","HURRYPOTTER"]
hashに対してmapメソッドを使う場合には、ブロック変数にkeyとvalueが代入されます。
hashのkeyまたはvalueを指定して、そのオブジェクトに対して、特定の処理を行うことも可能です。
この時、注意していただきたいのが、
返り値がhashだと期待しているとバグの原因になることがあるので注意しましょう。返り値はhashではなく配列オブジェクトとして返ってきます。
mapメソッドとwith_indexメソッドの併用
例えば、ある既存の配列に対して、その要素の先頭を大文字にして、通し番号を振るような処理を行いたい場合には、mapとwith_indexを組み合わせることで簡潔に書くことができます。
["tanaka","suzuki","sato"].map.with_index{|name, i| "#{i+1}番目: #{name.capitalize}"}
# =>["1番目: Tanaka", "2番目: Suzuki", "3番目: Sato"]
mapとwith_indexを組み合わせて使用すると、
ブロック変数として配列の要素とindexが使えるようになります。
「map.with_index」とすることでブロック内の引数 を2つとります。
第一引数に配列の要素、第二引数に番号を持ちます。
また配列オブジェクトをは最初の要素を0からカウントするので処理部分には「i+1」と書きます。
またcapitalizeメソッドは文字列オブジェクトの最初の文字を大文字にするメソッドです。
ブロック内でのnextの使い方
ブロック内で複雑な処理をする場合などに、
途中で特定の値を返したい場合は、nextを使用しましょう。
array = [1, 2, 3, 4, 5, 6, 7, 8,9] array = array.map do |num| next num if num.even? #=>複雑な処理 num*100 end p array # =>[100, 2, 300, 4, 500, 6, 700, 8, 900]
「next num」と記述することで、偶数の要素に対しては「num*100」という処理が行われず、既存の配列の値を返しています。
このように、mapメソッドのブロック内にnextを書くことによってreturnメソッドの働きをして、ブロック内の最終的な返り値を途中で変更することができます。
この場合ですと、nextメソッドの引数が最終的な返り値です。
map!メソッドの使い方
map!メソッドは、要素の個数分だけ式を実行し、結果をブロックの戻り値と入れ替えます。
mapは元の値はそのまま扱われますが、map!は元の値を書き換えます。
a.hoge(b)のようにメソッド呼び出しを行った際、aの値に影響を与えるメソッドのことをRubyでは一般的に「破壊的メソッド」と呼びます。
関連メソッドの紹介
- selectメソッド
selectメソッドは、mapメソッドと同様に、Enumerableモジュールに実装されたメソッドで、配列に対して使用します。
文字通り、条件を満たす要素を「選び」、その要素を基に新しい配列を作り出します。
a = [1,2,3,4,5,6,7,8,9,10]
p a.select{|num| num > 5} #5より大きい要素だけを取り出し、新しい配列を作り出す。
#=>[6,7,8,9,10]
- rejectメソッド
rejectメソッドもselectメソッド・mapメソッドと同様に、Enumerableモジュールに実装されたメソッドで、配列に対して使用します。
Enumerableモジュールとは、集合を表すクラスに数え上げや検索などのメソッドのパッケージのようなものです。
文字通り、条件を満たす要素を「取り除き」、残った要素を基に新しい配列を作り出します。
a = [1,2,3,4,5,6,7,8,9,10]
p a.reject{|num| num > 5} #5より大きい要素を取り除き、新しい配列を作り出す。
#=>[1,2,3,4,5]
この記事のハッシュタグ
まとめ
mapメソッドにかぎらず
Rubyにはたくさんの便利なメソッドが用意されているので、
記述が冗長になっているなと感じることがあれば普段から、
「よりよい方法は無いか、コード量を減らすことはできないか」
と検証してみることが大切です。
mapメソッドは基本的な使い方だけでも十分に便利なメソッドですが、
以上で見てきた応用的な使い方をマスターできれば、
少ない記述量で可読性の高いすっきりとしたコードが書けるようになるでしょう!
ぜひ普段の開発に取り入れてみてください。
はじめての転職、何から始めればいいか分からないなら

「そろそろ転職したいけれど、失敗はしたくない……」そんな方へ、テックキャンプでは読むだけでIT転職が有利になる限定資料を無料プレゼント中!
例えばこのような疑問はありませんか。
・未経験OKの求人へ応募するのは危ない?
・IT業界転職における“35歳限界説”は本当?
・手に職をつけて収入を安定させられる職種は?
資料では、転職でよくある疑問について丁寧に解説します。IT業界だけでなく、転職を考えている全ての方におすすめです。
「自分がIT業界に向いているかどうか」など、IT転職に興味がある方は無料カウンセリングにもお気軽にお申し込みください。





















