



プログラミングを勉強していく中で、正規表現という言葉に出会うことがあるかもしれません。
文字列から特定のパターンを抜き出したり、強力な検索機能を実装するためには、正規表現を使う必要があります。
この正規表現とは、一体何者なのでしょうか?この記事では、正規表現の正体から具体的な使い方まで、初心者の方にもわかりやすく解説していきます。
この記事の目次

正規表現とは?
正規表現とは、一言で言うと文字列のパターンを記述するための技術です。
英語では「Regular Expression」といい、「Regex」「RegExp」などと略されます。
とは言っても何がなんだかよくわかりませんよね。なのでまずは正規表現が使われている具体例をご紹介いたします。
Twitterに新規ユーザー登録するときのことを考えてみてください。
新規登録時には、ユーザー名・メールアドレス・パスワードの3つを入力する必要があります。ここで正しくない形式のメールアドレスを入力すると、「メールアドレスの形式がおかしいですよ!」と怒られてしまいます。
これは、正規表現を使い、文字列のパターンを検証することで実現している機能です。
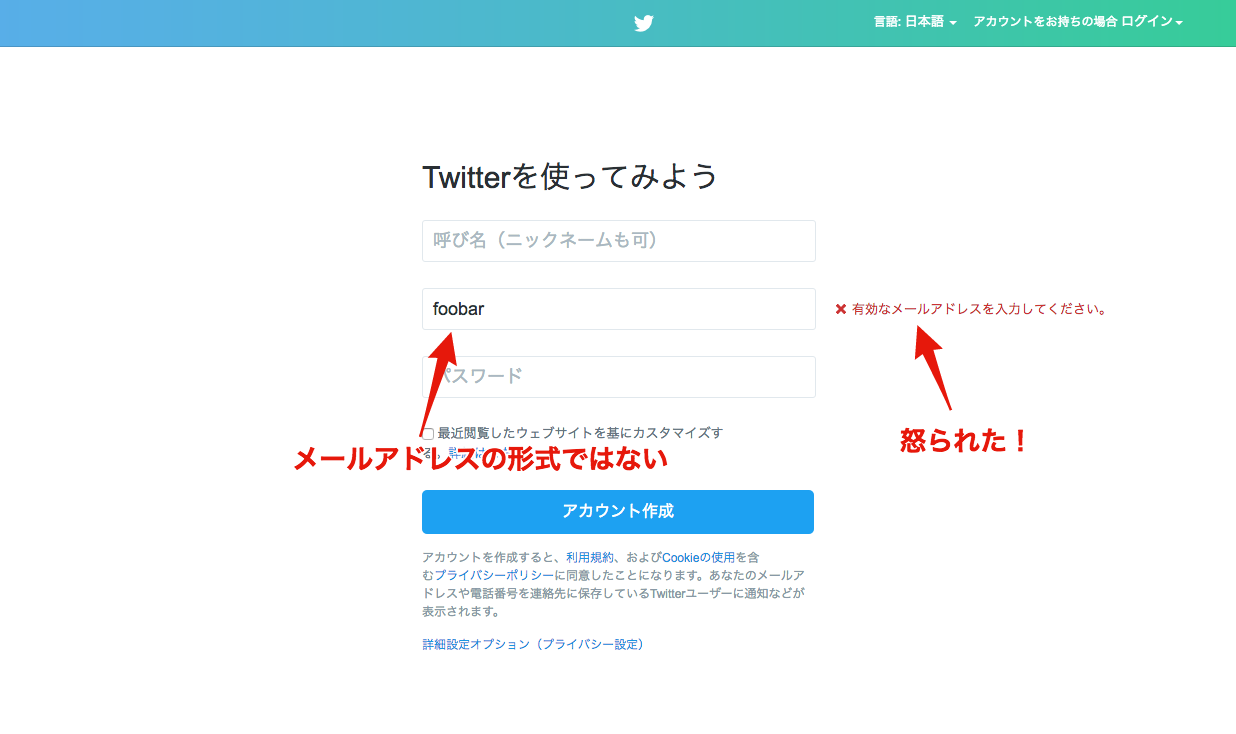
正規表現を使うことで、文字列のパターンを検証し、特定のフォーマットにマッチしないものは弾くことができるのです!
正規表現を適切に使えば、ユーザーから入力された情報が正しいフォーマットに沿っているかを確認することができるので、安全で確実なアプリケーションの運用ができます。
一方で、正規表現を使わず、ユーザーからの入力をすべて正しいものとして処理してしまうと、不正な値をデータベースに保存してしまったり、無効なメールアドレスを正しいものと認識してしまうなど、様々な問題が出てきます。
正規表現は、ユーザーから受け取った文字列を管理するうえで、欠かせない技術なのです!
正規表現の使い道が、なんとなくでも理解できましたでしょうか?この記事では、具体的な正規表現の使い方を解説していきます!
正規表現の書き方
正規表現は様々なプログラミング言語に実装されており、一度使い方を理解してしまえば多くの言語で使うことができます。今回は実行環境としてRubyを使います。
文字列のマッチング
ここで、「Hello, World!」という文字列にマッチする正規表現を実際に書いてみると、以下のようになります。
/Hello, World!/
あれ?っと拍子抜けした方もいるかもしれません。特定の文字列にマッチする正規表現は、こんなにも簡単に書くことができます。
正規表現は、スラッシュで囲むことで書くことができます。
実際にRubyで文字列が正規表現にマッチするかを検証するには、「=~」という演算子を使います。今回の例だと、以下のようになります。
'Hello, World!' =~ /Hello, World!/ # => 0
検証した結果、返り値として0が返っているのがわかります。
Rubyの演算子「=~」は、文字列と正規表現がマッチするかを検証し、検証した場合には、マッチした部分文字列の先頭の文字の、元の文字列内でのインデックス番号を返すのです。
Rubyではfalseとnil以外はすべてtrueと評価されますから、これはつまり、文字列と正規表現がマッチする場合、比較演算子「=~」で比較を行った結果はtrueと評価されるということです。
つまり、以下のような正規表現を使った比較をすると、7が返ります。
'Hello, World!' =~ /World/ # => 7

この性質を上手く活用すれば、この記事の最初で触れたメールアドレスの検証をRubyで実装することができます。
ちなみに、「=~」という演算子(メソッド)は、文字列・正規表現の両方に定義されているので、文字列のマッチングは以下のように書くこともできます。
/Hello, World!/ =~ 'Hello, World!' # => 0
この記事のハッシュタグ
もっと一般的な文字列のマッチング
これまでで、特定の文字列「Hello, World!」にマッチする正規表現を書くことができるようになりました。しかし、これだけでは「hello, world!」や「Hello World」といった、似た文字列にマッチすることができません。
regex = /Hello, World!/ 'hello, world!' =~ regex # => nil 'Hello World' =~ regex # => nil # 似た文字列にはマッチしない
そこで、ここではメタ文字と呼ばれるものを使い、より広範囲の文字列にマッチする正規表現を書いていきます。
似た文字列とは言っても「だいたい『Hello, World!』みたいな感じ」とコンピュータに指示することはできません。もっと具体的に、どのような形式の文字列にマッチするのかを定める必要があります。
今回は以下の要件で文字列をマッチングすることにします。
- 大文字と小文字は区別しない
- カンマ・エクスクラメーションマークは、それぞれあっても無くても良い
大文字と小文字は区別しない
まず、1. 大文字と小文字は区別しないを実装してみます。これはとても簡単で、正規表現のオプション修飾子というものを使うことで実現できます。具体的には、以下のように書きます。
/hello, world!/i
正規表現の最後のスラッシュのあとに「i」を書いただけです。(ちなみに、この「i」は「Ignore Case」の略です)ここで、実際にマッチングをしてみましょう。
regex = /hello, world!/i 'Hello, World!' =~ regex # => 0 'hello, world!' =~ regex # => 0 'HELLO, WORLD!' =~ regex # => 0
この例では、正規表現を「regex」という変数に代入したうえで様々なバリエーションの「Hello, World!」と比較をしています。返り値を見ると、すべて0になっており、見事にマッチしていることがわかります。
これで、1. 大文字と小文字は区別しないを実装することができました。
カンマ・エクスクラメーションマークは、それぞれあっても無くても良い
次に2. カンマ・エクスクラメーションマークは、それぞれあっても無くても良いを実装しましょう。ここで、正規表現の強力な機能であるメタ文字というものを使用します。
「メタ」とは「高次な−」「超−」というような意味の接頭辞ですから、「メタ文字」は普通の文字以上の意味を持った文字という意味になります。具体的に見ていきましょう。
今、「カンマ・エクスクラメーションマークは、それぞれあっても無くても良い」という条件を正規表現で表す必要があります。
これは言い換えると、「カンマ・エクスクラメーションマークが、それぞれ0回または1回登場すれば良い」ということになります。これは、「?」というメタ文字を使って以下のように表せます。
/Hello,? World!?/
このメタ文字「?」は、直前の文字(パターン)の0~1回の繰り返しにマッチします。つまり、この例だと「,」や「?」があっても無くてもマッチするということです。
実際にマッチするのか確かめてみましょう。
regex = /Hello,? World!?/ 'Hello, World!' =~ regex # => 0 'Hello World!' =~ regex # => 0 'Hello, World' =~ regex # => 0 'Hello World' =~ regex # => 0
見事にカンマ・エクスクラメーションマークのある無しにかかわらずマッチしていますね!これで、2. カンマ・エクスクラメーションマークは、それぞれあっても無くても良いを実装することができました。
完成した正規表現
これまでに学んできたオプション修飾子・メタ文字を組み合わせることで、最終的に以下のような正規表現を作ることができます。
regex = /hello,? world!?/i 'Hello, World!' =~ regex # => 0 'hello world' =~ regex # => 0 'HELLO, WORLD' =~ regex # => 0
この正規表現は、大文字と小文字は区別せず、カンマとエクスクラメーションマークのある無しにかかわらず文字列にマッチしています。
さいごに
実際のプログラミングでは、今回の例よりも複雑な正規表現を使うことが多くなります。しかし、この記事で紹介している基礎事項がしっかり理解できれば、だんだんと複雑な正規表現を作っていくことができるはずです!
以下に正規表現を勉強・実践する上で便利なリファレンスを載せておきますので、是非参考にしてみてください。
なお、紹介したリファレンスはJavaScriptでの実装について書かれていますが、正規表現の構文自体はRubyでも同様に実装されています。
はじめての転職、何から始めればいいか分からないなら

「そろそろ転職したいけれど、失敗はしたくない……」そんな方へ、テックキャンプでは読むだけでIT転職が有利になる限定資料を無料プレゼント中!
例えばこのような疑問はありませんか。
・未経験OKの求人へ応募するのは危ない?
・IT業界転職における“35歳限界説”は本当?
・手に職をつけて収入を安定させられる職種は?
資料では、転職でよくある疑問について丁寧に解説します。IT業界だけでなく、転職を考えている全ての方におすすめです。
「自分がIT業界に向いているかどうか」など、IT転職に興味がある方は無料カウンセリングにもお気軽にお申し込みください。




















