
Googleが開発した最新AIモデル「Gemini 3」は、2025年11月にリリースされ、その高性能ぶりが大きな話題になっています。
テキストだけでなく画像・音声・動画など複数のデータを扱えるマルチモーダル対応や、推論能力の大幅な向上、コード生成や自律的なエージェント機能など、数々の最先端機能を備えていますよ。
本記事では、Gemini 3の基本情報から特徴・機能、料金プラン、使い方、活用事例、他モデルとの比較、利用上の注意点まで徹底解説します。
初心者から上級者まで、Gemini 3を使いこなすための参考にしてください。

Gemini 3とは?基本情報を徹底解説

Gemini 3は、Google(DeepMind)による最新の大規模言語モデル(LLM)ファミリーです。
従来のモデル(PaLM 2やLaMDA)の後継として位置づけられ、2025年11月に正式リリースされました。
ここでは、Gemini 3の概要と注目される理由、さらに前世代2.5から3.0で強化・変更されたポイントを解説しますね。
Gemini 3の概要
Gemini 3はGoogle史上最もインテリジェントなAIモデルと称されるほど高度なモデル群です。
Google DeepMindの研究成果を結集し、テキストだけでなく画像・音声・動画・コードなど複数のデータ形式をネイティブに理解・生成できるマルチモーダルLLMとして開発されました。
入力としてテキストや画像、動画、音声、PDFまで受け取り、テキスト出力を行えるように作られています。
GeminiファミリーにはUltra(超大型モデル)、Pro(大型モデル)、Flash(高速度な軽量モデル)など複数のフレーバーがあります。
中でもGemini 3 Proは現時点での主力モデルであり、推論・マルチモーダル理解・コーディングなどあらゆる面で最高水準の性能を発揮しますよ。
Gemini 3が注目されている理由
Google Gemini 3がここまで注目を集める理由は、その機能・性能の飛躍的進化にあります。
まず、推論能力(Reasoning)が非常に高く、与えられた指示の背景にある文脈や意図まで深く理解できるように向上しました。
わずかなヒントから創造的アイデアの本質をつかんだり、複雑な問題に絡む複数の要素を解きほぐしたりするなど、深みとニュアンスを伴う高度な理解・推論が可能です。
次に、マルチモーダル対応という点も大きな特徴。
Gemini 3はテキストだけでなく画像や音声・動画までも理解・分析でき、例えば「手書きのレシピ(しかも多言語混在)を読み解いて翻訳し、きれいなレシピ文書を作成する」ことすら可能ですよ。
さらに、Googleの幅広いサービスへの統合も見逃せません。
Gemini 3はリリース初日からGoogle検索のAIモードに搭載されただけでなく、モバイルのGeminiアプリやGoogle AI Studio、企業向けのVertex AIなどあらゆるプラットフォームで一斉展開されました。
Gemini2.5から3.0で変わったこと
Gemini 3は前世代(Gemini2.5)から多方面で強化・進化しています。
Gemini2.5で「部分的に実現」されていた機能を、Gemini 3で総合的に統合し完成度を高めた点が大きな違い。
具体的には、推論・思考力の限界を押し広げることで、より複雑なタスクやアイデアへの対応力が向上しました。
Gemini 3では新機能として「Deep Thinkモード」が導入され、複雑な問題に対してさらに踏み込んだ深い思考を行えるようになっています。
また、生成UI(Generative UI)機能によって動的なインターフェースを自動生成できるようになった点も大きな進化です。
さらに、コンテキストウィンドウ(一度に処理できるテキスト量)が飛躍的に拡大。
Gemini 3 Proでは入力最大約1,048,576トークンという桁違いの長文を保持可能となり、数千ページに及ぶ文書全体を読み込ませて質問するといった利用も現実的になりました。

Gemini 3の特徴や機能
Gemini 3には、競合モデルを凌駕する様々な特徴・機能が搭載されています。
マルチモーダル理解や高度な推論(ThinkingLevel調整)、世界最高レベルのコーディング性能など、各機能のポイントを解説しますね。
ここでは、Gemini 3の代表的な特徴を順に見ていきましょう。
マルチモーダル理解の強化
Gemini 3最大の特徴の一つが、ネイティブにマルチモーダル(様々なデータ形式)を理解・生成できる点です。
他の多くのLLMがテキスト専門であるのに対し、Geminiは最初からテキスト以外の情報(画像、音声、動画、コードなど)も取り込んで学習されており、そのデータ理解範囲の広さが強みとなっています。
例えばユーザーはテキストだけでなく画像やPDFを入力として与えたり、Geminiアプリで音声で質問したりできますよ。
実際の応用例として、「家族伝来の手書きレシピ(異なる言語で書かれている)を読み取り翻訳して清書する」という作業は、画像認識+言語翻訳+文章生成を一度に行う高度なものですが、Gemini 3はこれを遂行できます。
また、「長時間の教育動画を与えて、その内容を習得するためのクイズカードや図解資料を作る」といった、一連の学習サポートコンテンツ生成もGeminiの得意分野です。
推論性能とThinkingLevelの向上
Gemini 3は推論能力(Reasoning)が大きく改善されており、これが高精度な回答や複雑な問題解決を可能にする大きな要因です。
ユーザープロンプトの背景にある文脈や意図を深く把握する力が大幅に高まっており、短い指示からでもユーザーの真のニーズを推察して適切なアウトプットを出せるようになりました。
Gemini 3ではこの推論能力の調整機構として「Thinking Level(思考レベル)」という概念が導入されています。
これは、モデルが回答生成時にどの程度じっくり思考プロセスを行うかを制御する仕組み。
高度な推論が不要な場面では思考レベルを「low」(低)に制限して高速応答させることも可能ですよ。
推論性能向上の成果は、各種ベンチマークスコアにも表れています。
Gemini 3 Proは総合的なLLM評価であるLMArenaにおいてEloスコア1501という前例のない高評価を獲得し、ランキング首位に立っています。
世界最高峰のコーディング性能
Gemini 3はプログラミング(コード生成・理解)能力においても現時点で世界最高水準と評価されています。
その卓越したコーディング性能は、単にコードを書くだけでなく、エージェント的にコードを実行・検証しながら開発を進めるという点で従来モデルを凌駕します。
GoogleはGemini 3を「これまでで最も強力なバイブコーディング(Vibe Coding)エージェント」であり、開発者の生産性を大きく改善させる存在だと述べていますよ。
具体的には、Gemini 3はユーザーの曖昧な要件から自律的にプロトタイプコードを作成し、必要に応じてそれを実行・検証して改良することが可能です。
Gemini 3のコーディング力はベンチマークにも表れており、ウェブ開発競技のWebDev ArenaではELO1487でリーダーボード首位を記録しています。
エージェント機能の強化
Geminiシリーズの画期的な特徴であるエージェント機能は、バージョン3.0でさらに強化されています。
エージェント機能とは、モデルが自分で外部ツールやシステムと連携し、複数のステップからなるタスクを自律的に遂行する能力を指します。
例えばウェブ検索を行ったり地図情報を取得したり、コードを実行したりといったアクションをAIが主体的に行い、ユーザーの目的達成をサポートしますよ。
特にGemini 3では、Google独自のツール群との連携がシームレスになりました。
Google検索やマップ、スプレッドシートやGmailといったサービスにGeminiが直接アクセスし、ユーザーデータを元に作業を行う「Gemini Extensions」という機能も利用できます。
GenerativeUIによる動的インターフェース
Generative UI(生成UI)は、Gemini 3がもたらす革新的なユーザー体験の一つです。
これは、AIモデルが単にテキスト回答を返すのではなく、回答にぴったりなユーザーインターフェース全体をその場で生成してしまうというもの。
例えば、「ファッションのコーディネートを提案して」と尋ねると、Geminiは単なる文章の説明ではなく、服の画像や組み合わせ例をレイアウトしたウェブページ風のビジュアルな提案画面を生成する、といった具合ですよ。
Gemini 3では、このGenerative UI機能がGeminiアプリの「Dynamic View」実験やGoogle検索のAIモードで試験展開されています。
ユーザーのプロンプトごとに没入型のビジュアル画面を自動生成するものです。
長文処理に強いコンテキストウィンドウ
Gemini 3は超長文の入力にも対応できる巨大なコンテキストウィンドウを持っています。
コンテキストウィンドウとは、一度の対話(プロンプト+生成)でモデルが保持できるテキスト量のこと。
Gemini 3 Proではこの上限が大幅に拡大され、入力で最大1,048,576トークン、出力で65,536トークンという驚異的な値になっていますよ。
トークンはおおよそ単語や記号の単位に相当するので、1Mトークンは数十万語、ページ数にして数千ページ分にも匹敵します。
これはGPT-4の32kトークンやClaude2の100kトークンなどを遥かに凌ぐ圧倒的な長さです。
Gemini 3の推論強化モード「Deep Think」とは?
Gemini 3の「Deep Think」モードは、通常版よりもさらに高度な推論処理を行う強化モードで、複雑な課題に対して多段的な思考チェーンを深く展開できるのが特徴です。
内部的にはモデルが行う検討ステップを増やし、文脈の因果関係や専門知識をより精密に統合することで、洞察を伴う回答を導きます。
Googleはこのモードを「Geminiの推論力とマルチモーダル理解力を最大化するモード」と位置づけており、難問への対応力が大幅に向上します。
- 複雑な推論課題で思考ステップを増強
- 高度専門領域(科学・数学・技術)で精度向上
- 画像・動画などのマルチモーダル理解も強化
- 通常モードより応答時間はやや長い
以下は、主要ベンチマークでの成果です。
| ベンチマーク | 成績 | 特徴 |
|---|---|---|
| ARC-AGI | 45.1% | 極めて難度の高い推論テストで前例のない高スコア |
| Humanity’s Last Exam | 通常Proを上回る | 多段推論・知識統合が強化 |
Deep ThinkはGoogle AI Ultraプランで利用可能ですが、現時点では米国・英語のみの提供となっています。
Gemini 3とPro / Ultra / Flashの違いを比較
Gemini 3には、モデル規模や用途に応じていくつかのバリエーションが存在します。
主なものがGemini Pro、Gemini Ultra、Gemini Flashの3つです。
ここではGemini 3におけるPro・Ultra・Flashの違いを比較して解説しますね。
Gemini Ultra(ウルトラ)の特徴
Gemini Ultraは超大型のGeminiモデルです。
具体的なパラメータ数等は公表されていませんが、Gemini Proよりも大きく高性能なモデルとして位置づけられていますよ。
開発段階では研究用や内部用に使われ、2025年時点では一般公開されていない可能性もあります。
Google DeepMindが構想する「最新のAI」に相当し、推論力・知識量ともに最高峰となるはずです。
将来的にDeep Thinkモード標準搭載や特定ドメインに特化した調整が行われることが示唆されています。
Gemini Pro(プロ)の特徴
Gemini Proは現在の主力モデルであり、Googleが一般に利用できるGemini 3の最高性能版です。
Gemini 2.0 Proは2024年にフラッグシップとして登場し、2025年11月にGemini 3 Proがリリースされました。
マルチモーダル理解や推論力、コーディング性能などバランス良く非常に高い水準にありますよ。
Gemini 3 Proは実際にGoogle検索のAIモードやGeminiアプリ、Workspace連携機能など幅広いプロダクトで利用されています。
言わばGeminiファミリーの中核であり、性能と安定性の両立が図られた汎用モデルと言えます。
Gemini Flash(フラッシュ)の特徴
Gemini Flashは高速・軽量版のGeminiモデルです。
大規模なProに比べてパラメータ数を削減・蒸留したモデルで、応答速度やコスト効率に優れていますよ。
そのぶん推論精度や知識量はProより劣るものの、日常的なシンプルタスクには十分な性能を発揮します。
Gemini Flashは大量リクエスト処理や低レイテンシが求められる用途にぴったりで、例えばチャット対応を大量に捌くシステムやモバイルデバイス上でのリアルタイム応答などに向いています。
Googleの説明では、Flashは価格性能比で優れた「万能モデル」であり、大規模処理やエージェント的ユースケースにぴったりとされています。
Gemini 3 Proの料金プラン
Gemini 3を利用するには、一般消費者向けのGoogle AIサブスクリプションプランか、開発者向けのAPI利用という2つの主な形態があります。
ここでは、個人ユーザー向けの無料版および有料プラン(Google AI Proプラン、Ultraプラン)で何ができるか、そして開発者がAPI経由で使う場合の料金体系について説明しますね。
用途や予算に応じてぴったりのプランを選びましょう。
無料版・無料でできること
結論から言えば、Gemini 3は無料でも基本的な利用が可能です。
Googleアカウントさえあれば誰でも使える無料枠が用意されており、日常的な範囲であれば料金を払わずGeminiのAI機能を試せますよ。
無料版では、Geminiアプリ(または検索のAIモード)でGemini2.5 Flashモデルを中心としたやりとりができ、限定的ながらGemini3 Proモデルの機能に触れることもできます。
具体的な無料利用の内容としては、パーソナルAIアシスタントとしてGeminiとチャットができる、テキストから画像を生成する機能が使える、ウェブ検索と連動して詳細に調べ物をする「Deep Research」機能も利用可能などがあります。
ただし無料版にはいくつか制限もあり、アクセスできるモデルがGemini2.5 Flashがメインとなり、Gemini3 Proは限定的にしか使えません。
Geminiを使いこなすなら、使い方を学ぶのが最短ルート
Gemini 3.0は無料でも使えますが、「なんとなく使っている」だけでは仕事や副業への活用は難しいのが現実です。
テックキャンプ AIカレッジでは、GeminiやChatGPTなど最新の生成AIを実務で使いこなすスキルを、未経験から体系的に学べます。
400以上のカリキュラムが定額で学び放題。週3回のオンラインセミナーで最新情報にもキャッチアップできます。
「AIを使える人材」になって、副業・キャリアアップを目指したい方はまず無料相談から。
▶ テックキャンプ AIカレッジの詳細を見る(無料相談・資料請求あり)
Google AI Plus(¥1,200/月)
Google AI Pro(¥2,900/月)
Google AI Proプランは、Gemini 3を本格的に使いたい個人ユーザー向けの有料サブスクリプション。
月額料金は¥2,900/月です。
Proプランに加入すると、無料版では制限のあった様々な機能やモデルへの高いアクセス権限が解放され、生産性や創造性を一段上のレベルで引き出すことができます。
Google AI Proプランで利用可能になる主なメリットとして、Gemini 3 Proモデルへのフルアクセス、Deep Research強化、Veo 3.1 Fastによる動画生成、毎月1,000 AIクレジット、Gemini Code Assist / CLIの上限引き上げ、Google Antigravityのレート制限引き上げ、Google Home Premiumなどがあります。
Google AI Ultra(¥36,400/月)
Google AI Ultraプランは、Proを上回る最上級のサブスクリプションです。
価格は、月額¥36,400/月(3ヶ月割引適用で¥18,000/月)と非常に高額で、想定ユーザーは熱心なパワーユーザーや企業、小規模開発チームなど。
UltraプランではGeminiの持つ最高レベルのモデル・機能に加え、独占的な新機能が利用可能になります。
Ultraプランの特典はProの全機能に加えて、Deep Think・Gemini Agentの利用(米国・英語のみ)、Veo 3.1による動画生成フルアクセス、毎月25,000 AIクレジット、Google Antigravityのレート制限最大化などがあります。
特典としてYouTube Premium個人プラン(40か国以上で提供)が無料付帯し、クラウドストレージは30TBに拡張されます。
API料金
開発者がGemini 3をAPI経由で自分のアプリやサービスに組み込む場合、料金は従量課金制(使った分だけ支払う)となっています。
Googleはまず開発者向けに太っ腹な無料利用枠を用意しており、少量のトークン(入力/出力テキスト量)であれば無料で試せますよ。
本格的にアプリに組み込む際は有料のPay-as-you-go(従量課金)に移行します。
料金体系は1メガトークン(100万トークン)単位で設定されており、モデルの種類や入出力によって単価が異なります。
例えば、Gemini 3 ProプレビューモデルのAPI料金は、入力が100万トークンあたり$2.00(プロンプト≤200Kトークン)/$4.00(>200Kトークン)、出力が$12.00(≤200K)/$18.00(>200K)となっています。
Gemini 3の使い方
ここからは、実際にGemini 3を使う方法について解説します。
Gemini 3はGoogleの各種サービスや専用アプリ、開発者ツールなど幅広い経路で利用できますよ。
代表的な使い方として、Geminiアプリ/ウェブ版での利用、Google検索のAIモードでの利用、Google AI Studioでの開発利用、Antigravityでの自律開発環境の利用、Gemini CLIでのコマンドライン利用を紹介します。

Geminiアプリ・Web版での使い方
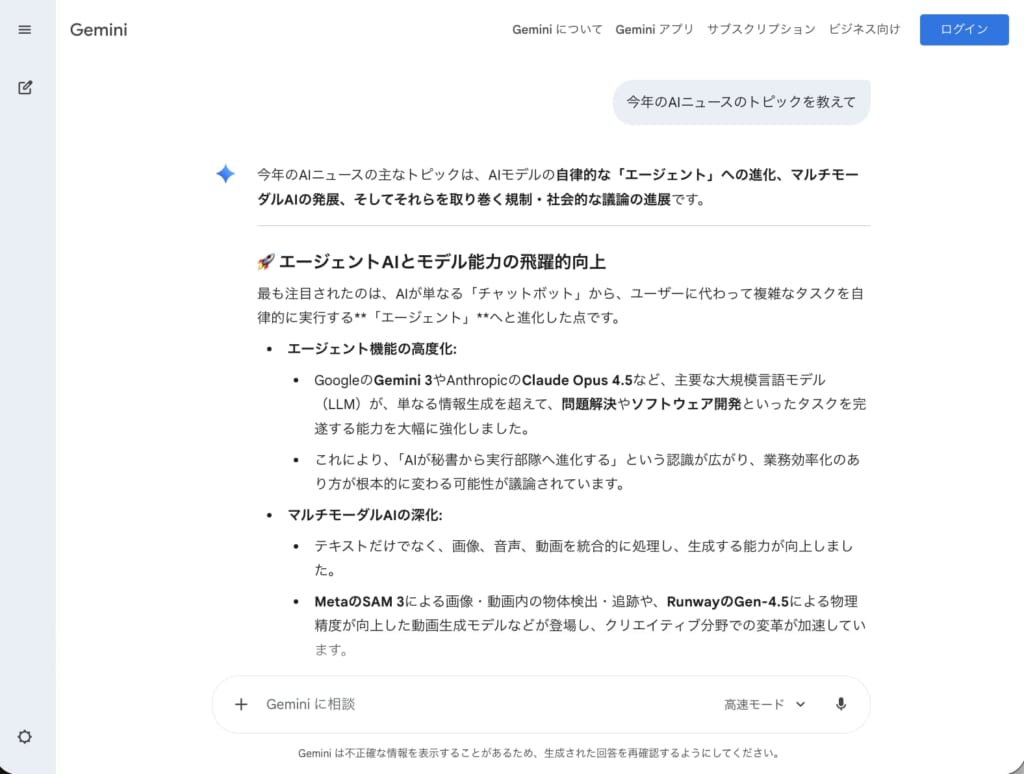
最も手軽にGemini 3を体験する方法が、Geminiアプリ(モバイル)またはGemini Web版を使うことです。
GeminiはかつてのGoogle Bardに代わる新AIチャットボットとして用意されており、gemini.google.comというウェブサイトや、Android/iOS向けのGemini専用アプリからアクセスできますよ。
スマホの場合(Geminiアプリ)は、AndroidではGoogleアシスタントアプリがGeminiアプリに置き換わっています。
Playストアから最新のGeminiアプリを入手し起動すると、画面下部の入力欄にメッセージを入力してAIとのチャットを開始できます。
PCの場合(Web版)はGemini Web(gemini.google.com)にアクセスし、Googleアカウントでログインすればすぐに使えます。
Geminiの基本操作はわかった。
でも「どうすれば仕事や副業に活かせるか」がわからない、そんな方は多いです。
テックキャンプ AIカレッジでは、Geminiをはじめとする生成AIを「実際に稼ぐ・評価される」レベルまで活用するスキルをオンラインで学べます。
未経験から副業案件を獲得した受講生も多数。自分のペースで学べるレギュラープランと、短期集中プランの2コースを用意しています。
まずは無料で資料だけでも見てみませんか?
AI Mode(Google検索)での使い方
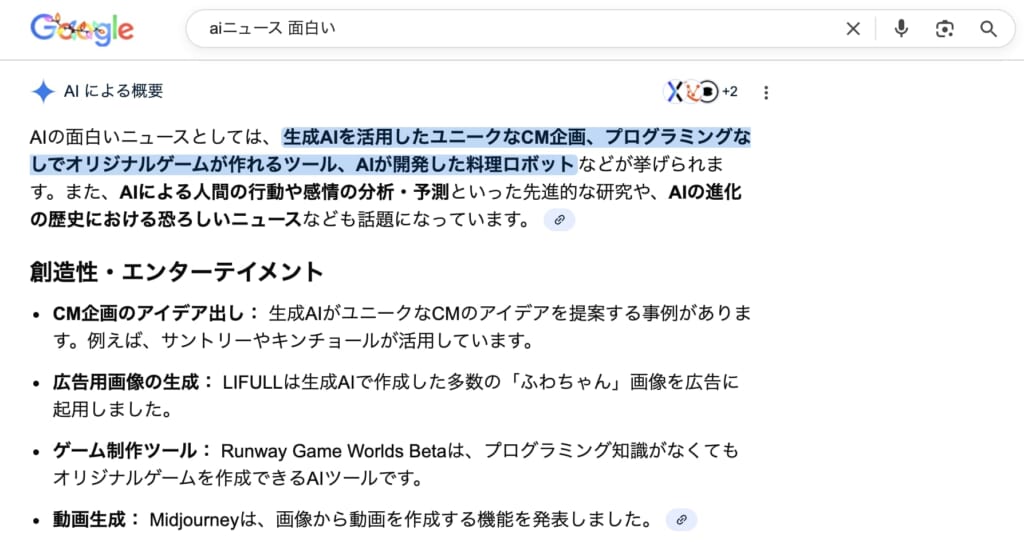
Google検索のAIモード(AI Overviews)を利用することで、検索エンジンにGemini 3のパワーを統合した新しい検索体験が可能です。
AIモードを有効にすると、通常の検索結果に加えてGeminiによる要約・回答が検索画面上部に表示されますよ。
現在この機能は一部地域・ユーザー向けの提供ですが、日本でも試験提供が開始されました。
AIモードの有効化は、パソコンの場合Google検索設定で「生成AIによる検索体験を試す」をオンにします。
AIモードではGemini 3が検索結果をリアルタイムに取得し参照するため、最新のニュースやウェブ情報にも対応できるのが強みです。
Google AI Studioでの使い方
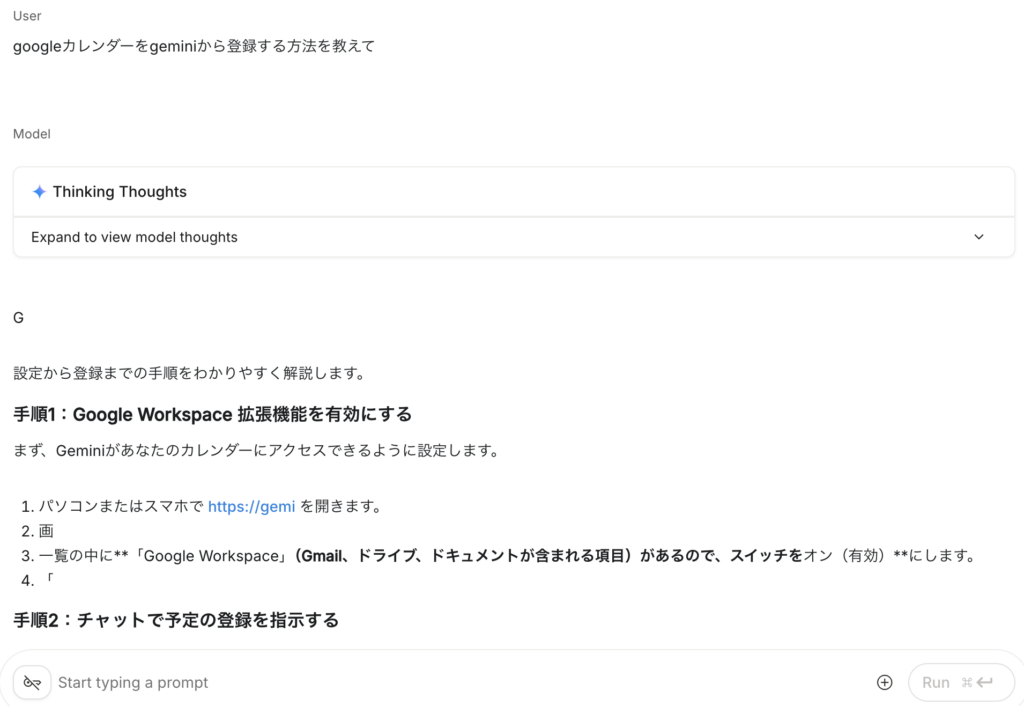
Google AI Studioは、開発者や上級ユーザー向けのGemini活用プラットフォームです。
AI Studio上でGemini APIを試したり、自分のデータでカスタムAIを構築したりすることができますよ。
要するにAIのプレイグラウンド兼開発環境であり、OpenAIのPlaygroundに相当する存在です。
Google AI Studioを使うには、まずaistudio.google.comにアクセスしてログインします。
ここでGemini API用のAPIキー発行も行え、テキストプロンプトを入力してGeminiの出力を得ることができます。
Antigravityでの使い方
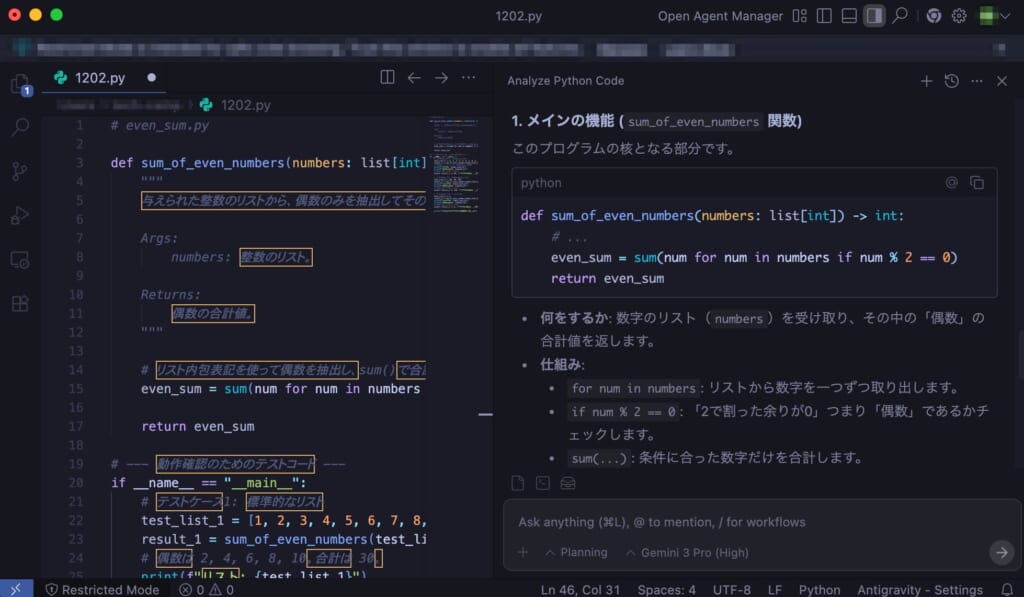
Google AntigravityはGemini 3を搭載した新しいエージェントファーストの開発環境です。
これは従来のIDE(統合開発環境)にAIエージェントを深く組み込んだもので、開発者が自然言語で指示を出すと、AIが自律的にコードを書き、実行し、必要に応じて修正まで行ってくれる革新的なプラットフォームとなっていますよ。
Antigravityの利用を開始するには、まずGoogle側の専用環境(現在は一部プレビュー)にアクセスします。
AntigravityはGoogle AI Proプラン以上で利用可能(Proでレート制限引き上げ、Ultraで最大化)。Google AI公式プランページにて正式サービスとして案内されています。
使い方は人間の同僚プログラマーに指示する感覚に近く、例えば「Reactを使ってシンプルなToDoリストアプリを作って」とエージェントに依頼すると、Geminiが自律的にプロジェクトを開始します。
Google CLIでの使い方
Gemini CLI(Google AI CLI)は、Geminiの力をコマンドラインから利用できるツールです。
開発者や上級ユーザーが日常的に使うターミナルに、AIの知見と自動化能力を統合することを目的に作られていますよ。
要は「対話型AI搭載のターミナルアシスタント」のようなものです。
Gemini CLIを使うには、まず対応するパッケージをインストールします(GitHub上で公開されているGemini CLIツールをnpmやpipで導入する形などが想定されています)。
Gemini CLIの特徴は、非常に柔軟であること。コーディングからコンテンツ生成、システム操作まで幅広いニーズに応えてくれます。
Gemini 3の活用事例

Gemini 3の強力な機能は、実際のビジネスやプロジェクトでどのように活用できるのでしょうか。
マルチモーダルやエージェント、Generative UI、超長文処理などの特徴を活かしたユースケースは幅広く考えられますよ。
ここでは想定される活用事例をいくつか紹介します。
Generative UIによる自動インターフェース生成型データ分析システム
Gemini 3のGenerative UI機能を活用すれば、ユーザーの要望に応じてAIが即座に分析用インターフェースを生成するシステムが実現できます。
例えば社内に大量のデータが蓄積されているものの、専門的なBIツールの使い方がわからない社員が多いとしますよ。
この場合、Gemini 3をバックエンドに据えた対話型システムを構築すれば、社員はただ「先月の売上データを地域別にグラフで見せて」と問いかけるだけでOKです。
Gemini 3はそのリクエスト内容を理解し、社内データベースから該当する売上データを取得するようエージェントに指示し、さらに結果をわかりやすく可視化するダッシュボードUIをリアルタイムに作り出します。
従来であればエンジニアやアナリストがダッシュボードを作って利用できるようにする必要がありましたが、Gemini 3ならユーザーの質問内容に合わせてUIそのものをAIが生成するため、事前準備不要で柔軟性抜群です。
Vibe Codingによる自然言語からの高速プロトタイプ開発
Gemini 3のVibe Coding機能を活かすことで、自然言語の指示からほぼ自動でアプリケーションのプロトタイプを作り上げることができます。
これはスタートアップのプロダクト開発や、新規機能の社内デモ作成などにおいて極めて有用な事例ですよ。
例えば、とある企画担当者がスマホ向けの新サービスを思いついたとします。
その人はエンジニアではないため詳細なコードは書けませんが、Gemini 3に対して「ユーザーが写真を投稿してコメントし合えるSNSアプリを作って」と依頼してみました。
するとGeminiはゼロショット生成の能力を発揮し、まず必要な機能リスト(ユーザープロフィール、写真アップロード、コメント欄など)を洗い出し、Vibe Codingモードでフロントエンドの画面コードを生成します。
Agent機能による自律的な業務代行ボット
Gemini 3のエージェント機能を用いれば、特定の反復業務を自律的にこなすボットを構築することができます。
例えば、カスタマーサポート担当者の負担を減らすために、Gemini 3を活用した自律型サポートボットを導入するイメージですよ。
このボットは顧客からの問い合わせメールを受け取ると、まずGeminiエージェントがメール本文を読み取ります。
次に社内ナレッジ(製品マニュアルやFAQデータベース)を横断検索し、適切な回答を生成します。
Gemini 3の長文処理能力により、該当する資料が何十ページあっても瞬時に要点を掴み、メール返信文を下書きし、担当者のトーンや社風に合うよう調整します。
超長文処理による全社ドキュメント横断型ナレッジ検索
Gemini 3の長大なコンテキストウィンドウを活かし、社内に点在する膨大な文書を一括で横断検索するナレッジシステムを構築することができます。
大企業では社内Wiki、技術仕様書、顧客とのメール、議事録など様々な文書が蓄積されていますが、それらがサイロ化し必要な知識に辿り着けないことがしばしば起こりますよ。
Gemini 3なら、この問題を解決する統合ナレッジAIとして機能できます。
具体的には、まず社内の主要ドキュメント(PDF数千ページ分やデータベース数GB分)をGeminiにインデックスさせます。
ユーザーがシステムに自然文で質問を投げかけると、Geminiは関係ありそうな社内文書全てから回答を探しに行きます。
Antigravityを使ったAI主導のアプリ自動構築環境
Antigravityプラットフォームを応用し、AI主導でアプリケーションを自動構築していく開発環境を事例として考えてみます。
これは、従来のCI/CD(継続的インテグレーション/デプロイ)のフローにAIエージェントを組み込み、人間はレビューと最終承認だけを行うような未来的な開発スタイルですよ。
例えばあるソフトウェアプロジェクトで新機能を追加する場合、まずプロダクトマネージャーが要件を自然言語でAntigravity内のGeminiエージェントに伝えます。
「ユーザープロフィール編集機能を追加したい。ユーザーが名前とアバター画像を変更できるようにして」といった具合です。
Geminiエージェントは現行のコードベースを把握しているので、まず影響範囲を分析し、必要なコードを書き足し、UIコンポーネントを生成し、サーバーサイドのAPIエンドポイントを追加し、テストコードも作成します。
Gemini 3とChatGPT・Claudeの性能比較

Google Gemini 3はOpenAIのChatGPT(GPT-4/5)やAnthropicのClaudeといった他社先進モデルと比べて、どのような位置づけにあるのでしょうか。
簡潔に言えば、Gemini 3は現時点で総合力においてトップクラスとの評価が多いですよ。
ここでは、主要なAIモデルとの比較ポイントを解説します。
知識正確性の比較
| モデル名 | 知識スコア | 結果・順位 |
|---|---|---|
| Gemini 3 Pro | 13.0 | 1位 |
| Claude 4.1 Opus | 4.8 | 2位 |
| GPT-5.1系 | 2.0 | 3位 |
出典:Artificial Analysis (2025.11)。スコアが高いほど、幅広い知識に対して正確な回答ができたことを示します。
AIモデルの知識正確性を測る新ベンチマークでは、Gemini 3 ProがOmniscience Indexスコア13点で圧倒的首位を獲得しました。
2位のClaude 4.1 Opus(4.8点)やOpenAI GPT-5.1系モデルを大きく引き離しています。
これはGeminiの正答率・網羅性の高さを示すものですよ。
一方で、ハルシネーション(事実誤り)率は依然として各モデルの課題です。
先のベンチマークによるとGemini 3 Proの誤答中88%に事実誤認が含まれており、これは前世代のGemini 2.5と同程度でChatGPTやClaudeと比べても特段低くはありません。
マルチモーダル対応の比較
| モデル名 | 特徴・得意スタイル | 向いている使い方 |
|---|---|---|
| Gemini 3.0 | 【マルチ・ネイティブ】 動画ファイルや音声データを「そのまま」理解するのが得意です。 人間と同じように映画を見たり音楽を聴いたりできます。 | 長い動画の要約、会議録音の分析 画像・音声が混ざった資料の整理 |
| GPT-5.2 | 【バランス型】 画像認識の精度が高く、会話(音声対話)も流暢です。 | 写真の内容説明、リアルタイムでの音声英会話、グラフの読み取り |
| Claude Opus 4.6 | 【視覚・読解型】 画像とテキストを組み合わせた分析が非常に丁寧です。 動画や音声の直接入力には対応していませんが、静止画の読み取り精度はピカイチです。 | 手書きメモの文字起こし、図解マニュアルの読み込み、スクリーンショットからのコード作成 |
Gemini 3.0のマルチモーダル対応は、ライバル機種とは設計のアプローチが異なります。
GPT-5.1系やClaude 4.1も画像認識の性能は高く、写真の内容を説明したりグラフを読み取ったりするのは得意です。
一方で、Geminiは最初から「画像・音声・動画」をすべて統合して処理できるように設計(ネイティブ対応)されている点が大きな特徴です。
そのため、「長い動画ファイルをそのまま読み込ませて要約する」あるいは「音声データから直接ニュアンスを汲み取る」といった作業においては、Geminiが特に強みを発揮します。
コンテキスト長とコーディング性能の比較
| モデル名 | 特徴・得意スタイル | 向いている使い方 |
|---|---|---|
| Gemini 3.0 | 【大容量 + 実行力】 100万トークンという記憶力に加え、「どうすれば解決できるか」を自律的に考える力(エージェント性能)が高いです。 大量のファイルを読み込み、複雑な改修を丸ごと任せられます。 | 大規模なプログラム全体の修正、大量の社内マニュアルからの検索、過去の議事録すべての分析 |
| GPT-5.1系 | 【標準・高精度】 記憶できる量は標準的(12.8万トークン)ですが、論理的思考力が強く、複雑な難問を解く力に安定感があります。 | 新しい機能のプログラミング、バグ(不具合)の原因究明、短いコードの生成 |
| Claude 4.1 | 【長文・高精細】 GPTより多い記憶量(20万トークン)を持ち、特に「指示を忠実に守る」能力が高いです。 綺麗なコードを書くのが得意です。 | 設計書に忠実なコーディング、長い論文の要約・執筆、自然な日本語文章の作成 |
コンテキスト長(一度に扱える情報量)についても、各社の個性が分かれています。
Claude 4.1が約20万トークン、GPT-5.1系が12.8万トークンと、一般的なビジネス文書を扱うには十分な容量を持っていますが、Gemini 3.0 Proは実に100万トークン超に対応しています。
これは「本を数冊読む」のと「図書館の棚ごと分析する」のと同じくらいの差があり、膨大なマニュアルや過去の全議事録を一気に解析するようなタスクでは、Geminiの容量が物理的な強みとなります。
また、コーディング性能についても、GoogleはWebDev Arenaなどの最新ベンチマークにおいて、エージェント(自律的なプログラム作成)タスクでGPT-4世代を上回る実績を公表しています。
GeminiもChatGPTも、使いこなせる人が圧倒的に有利
どのAIが優れているかより大切なのは、「AIを仕事に活かせるスキル」を持っているかどうかです。
比較記事を読み漁っても、使えなければ意味がありません。
テックキャンプ AIカレッジなら、ChatGPT・Gemini・Cursor・Difyなど主要なAIツールを横断的に学べます。
単なるツールの使い方だけでなく、「副業案件を取れる実力」まで育てるカリキュラムが特徴です。
AIの波に乗り遅れる前に、今すぐスキルを身につけましょう。
Gemini 3を使うときの注意点
優れたGemini 3も万能ではなく、利用に際して注意すべき点がいくつか存在します。
特に重要なのは、出力内容の正確性検証と機密情報の取扱い、そして高度な自律機能のコントロールやコスト管理ですよ。
ここでは、Gemini 3を安全かつ効果的に活用するために押さえておきたいポイントを説明します。
情報の正確性を必ず検証する
Gemini 3の回答は一見もっともらしく高度ですが、必ずしもすべて正確とは限りません。
いわゆる「幻覚(ハルシネーション)」と呼ばれるAIの誤回答は、最新モデルでも完全には解消されていませんよ。
実際、Google CEOのスンダー・ピチャイ氏も「生成AIを盲信しないことが非常に重要だ。彼ら(AI)は極めて誤りを犯しやすい」と警鐘を鳴らしています。
従って、Gemini 3から得られた情報は鵜呑みにせず裏付けを取る姿勢が必要です。
特に事実関係が問われる場面では注意が要り、法的な助言や医療分野の回答については、必ず専門家の確認を仰ぐか、公式な情報源で正確性を検証しましょう。
機密情報・個人情報の入力は避ける
Gemini 3を利用する際、機密データや個人情報を不用意に入力しないことが大切です。
AIへのプロンプトとして送信した内容はクラウド上に渡り、場合によってはログや学習データとして扱われる可能性がありますよ。
特に無料プランや開発者の無料枠で使用する場合、入力コンテンツがモデル改善目的で保存・解析され得るという注記があります。
つまり、自社の極秘プロジェクト情報や個人の機微な情報をAIに投げかけるのはリスクがあります。
法律上保護される個人情報(氏名・住所・連絡先・ID番号等)や企業の重要秘密(開発中製品の仕様、取引先リスト等)は、原則としてGeminiへの入力を避けるべきです。
高度機能(Dynamic View / Generative UI / Agent)の暴走防止
Gemini 3はDynamic View(動的ビュー)やGenerative UI、エージェント機能など高度で自律性の高い機能を備えていますが、これらを使う際には暴走を防ぐための管理が欠かせません。
AIが意図せぬ方向に動作しないよう、人間側でフェイルセーフを設けておく必要がありますよ。
エージェント機能ではさらに強い監督が求められます。
Gemini 3エージェントはツールを自律的に使えるため、例えば外部システムに誤った操作をしてしまうリスクもゼロではありません。
現状、Gemini Agentは「ユーザーの管理と指導の下で」動作することを前提としており、人間が常にモニタリングし、怪しい挙動があれば即停止できる体制が望ましいです。
API利用時のコストとコンテキスト上限
Gemini 3をAPI経由で利用する場合、コスト管理とコンテキスト長の扱いに注意が必要です。
まずコスト面について、Gemini APIは従量課金制であり、大きなモデルや大量トークンを処理するとそれだけ料金が嵩みますよ。
特にGemini 3 Proのような高性能モデルは、入力1Mトークンあたり$2程度、出力も含めれば合計数ドルになる計算です。
対策として、APIの利用制限を設定することが重要です。
開発中はプロジェクトごとに予算上限を決め、超えそうになったらアラートを出す仕組みを作りましょう。
Gemini 3に関するよくある質問
Gemini 3について、よく寄せられる質問をまとめました。
導入前の疑問や不安を解消する参考にしてください。
- Gemini 3が無料でできることはありますか?
-
はい、Gemini 3には無料で利用できるプランがあり、基本的なAIアシスタント機能を試すことができます。無料版ではGemini 2.5 Flashモデルによる日常的な質問応答や画像生成、ウェブ検索を用いた調べ物(Deep Research機能)などが一定範囲で可能です。限定的ながらGemini 3 Proモデルへのアクセスも含まれており、無料でも高度な回答を得られる場合があります。
- Gemini 3は無料プランでも使えますか?
-
はい、Gemini 3は無料プランでも利用可能です。Googleアカウントさえあれば追加料金なしでGeminiアプリ(モバイル/ウェブ)や検索のAIモードを使って対話できます。ただし無料プランでは高度なモデル利用や大量リクエストに制限があり、優先度も有料ユーザーより低く設定されています。
- Gemini 3のリリース日はいつ?
-
Gemini 3は2025年11月18日に正式リリースされました。Googleの公式ブログやCloud Nextイベントにおいて発表され、同日からGoogle検索のAIモードやGeminiアプリ、Vertex AIなど各種サービスで順次利用できるようになっています。
- 無料のGemini 3の使用には制限がありますか?
-
はい、無料版Gemini 3にはいくつかの制限があります。まず、利用できるモデルがGemini 2.5 Flash中心となり、最新のGemini 3 Proモデルは一部機能でのみ限定的に触れられる程度です。また利用回数やトークン数にも上限があり、一日に送信できるプロンプト数や生成できる文字数が制約されています。
- GeminiとChatGPTはどっちがいい?
-
用途によりますが、高度な推論やマルチモーダル処理ではGemini 3が優れています。Gemini 3は画像・音声も扱え、推論力も最先端で、長大なコンテキスト処理や自律エージェント機能など機能面でリードしています。一方、ChatGPTは会話の自然さや創造的な文章生成で定評があり、UIの手軽さも魅力です。自分のニーズに合わせて使い分けるのがベストです。
- Gemini Proの何がすごいの?
-
Gemini 3 ProはGoogle史上最も高性能なAIモデルである点がすごいと言えます。マルチモーダルな理解能力は世界トップクラスで、テキストだけでなく画像・動画・音声・コードまで幅広く扱えます。さらに推論力が非常に高く、複雑な問題でも人間専門家レベルの洞察を示します。コーディング性能も突出しており、自律的にコードを書いて実行・修正できるエージェント機能を備えています。
- Gemini 3はスマホで使えますか?
-
はい、Gemini 3はスマートフォンでも利用可能です。Androidでは「Gemini」アプリが利用でき、従来のGoogleアシスタントアプリに代わってインストールできます。iPhoneでもGoogleアプリやGoogle検索アプリ内でGeminiが統合されており、それらを通じてGemini 3にアクセスできます。テキスト入力はもちろん、マイクを使った音声入力や画像を撮影しての質問も可能です。
- Gemini 3はPCで使えますか?
-
はい、Gemini 3はPCからも利用できます。公式のGemini Web版が公開されており、ブラウザでgemini.google.comにアクセスしてログインすればPC上でGeminiとのチャットが可能です。またGmailやGoogleドキュメント、スプレッドシートなどのGoogle WorkspaceアプリにもGeminiが統合されており、PC上でメール文の下書き作成やドキュメント要約なども行えます。
- Antigravityとはなんですか?
-
Antigravityは、Gemini 3を搭載した新しいエージェント指向の開発プラットフォームです。従来のIDE(統合開発環境)にAIエージェントを組み込み、開発者の指示に応じてAIが自律的にコードを書いたり実行したりできるのが特徴です。AntigravityではGemini 3の高度な推論力やツール使用能力を活用し、AIを能動的なパートナーとしてソフトウェア開発を進められます。
まとめ
Gemini 3はGoogleの最新AIモデルであり、その能力と可能性は非常に大きなものがあります。
リリース以来、マルチモーダル対応や高度な推論力、動的インターフェース生成や自律エージェント機能など、多方面で革新的な機能を示してきました。
特に画像・音声も理解できる世界最高レベルの知性と、1百万トークンを超える巨大な文脈も扱える容量は、他のモデルにはないGemini 3ならではの強み。
一方で、Gemini 3を安全かつ効果的に使うためのポイントも見えてきました。
AIの回答を過信せず、人間が検証・管理することの重要性があり、優秀なAIであっても誤情報を含む可能性があるため、また機密データの取り扱いや自律機能の挙動には注意が必要です。
ChatGPTやClaudeといった他モデルとの比較では、Gemini 3は総合的に最先端であるとの評価が多いですが、それぞれの長所短所を理解して状況に応じた使い分けが望ましいでしょう。
Gemini 3はGoogle検索やモバイルアプリ、クラウドAPIなど様々な形で利用でき、一般ユーザーから開発者まで幅広くメリットを得られます。
無料でも基本機能を試せる一方、ProやUltraプランではその真価を存分に引き出すことが可能です。
Gemini 3がもたらす可能性に期待しつつ、賢く安全にその力を活用していきましょう。







