
日々の会議や取材音声を手作業で文字に起こすのは、時間も手間もかかる大変な作業ですよね。
Googleが開発した生成AI「Gemini」を使えば、こうした音声データを短時間で正確にテキスト化できます。
専用ソフトや外注に頼らず、Google AI Studioという無料のウェブツールで誰でも手軽に試せるのも魅力。
本記事では、Geminiで文字起こしを行う具体的な方法から、活用事例・プロンプトのコツを徹底解説します。

Gemini(Google AI Studio)で文字起こしを行う方法
誰でも使えるGoogle AI Studio上でGeminiを活用すれば、煩雑な音声の文字起こし作業を自動化できます。
ここでは、Google AI Studioで実際に音声・動画ファイルを文字起こしする具体的な手順を紹介しますね。
初めてGeminiを使う方でも分かるように、ファイルの準備から結果の整形まで5つのステップに沿って解説していきます。
Step 1:Google AI Studioにアクセスする

まずはお使いのブラウザからGoogle AI Studioにアクセスし、Googleアカウントでログインしてください。
Google AI Studioはインストールは不要で、ウェブ上でそのまま使い始められます。
初期表示が英語の場合は、画面を右クリックして「日本語に翻訳」を選ぶと分かりやすくなりますよ。
ログイン後、新規プロジェクト(チャットセッション)を作成し、使用するモデルとしてGeminiを選んでください。
高精度なGemini Proや高速なGemini Flashなど、用途に合わせてモデルを選べます。
これで文字起こしの準備となる環境が整いました。
Step 2:文字起こししたい音声・動画ファイルを準備する
次に、Geminiに読み込ませる音声または動画ファイルを用意しましょう。
ファイルはGoogle AI Studioでサポートされている形式である必要があります。
対応フォーマットには、音声ならMP3・WAV・FLAC・OGG・AAC、動画ならMP4・AVI・MOV・WebM・MPEG・WMV・3GPPなど主要な形式が含まれますよ。
ファイルサイズや長さにも注意が必要で、長時間の音声を一度に処理しようとすると出力が途中で途切れる場合があります。
そのため、1回のリクエストあたり数時間を超えるような録音は、必要に応じて複数のファイルに分割しておくのがおすすめです。
また、音源の内容に応じて、事前に話者名や専門用語の綴りをメモしておくと後の工程がスムーズになります。
Step 3:音声・動画ファイルをアップロードする
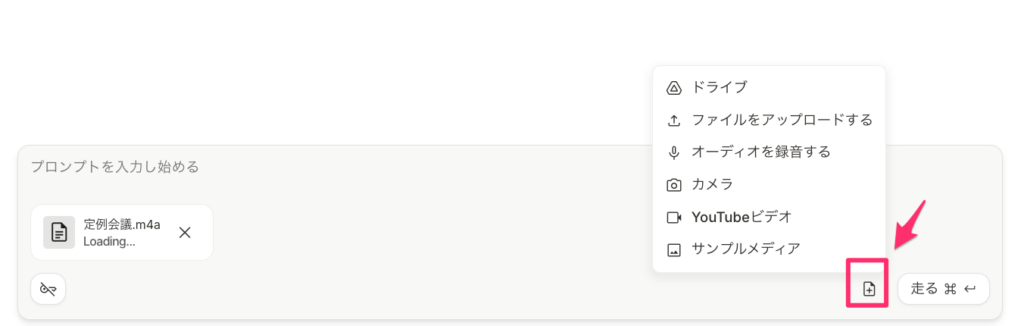
準備したファイルをGoogle AI Studioにアップロードします。
入力欄右下の「Upload File」ボタン(日本語の場合は「ファイルをアップロードする」)をクリックし、先ほど用意した音声ファイルや動画ファイルを選んでください。
アップロードが完了すると、AIがその音声データを分析可能な状態になります。
たとえば会議の録音データを指定すれば、Geminiがファイル全体を読み込める準備が整うということですね。
なお、一度にアップロードできるファイル数やサイズには上限がある点に注意しましょう。
AI Studioでは1ファイル最大2GBまで、同時に最大10ファイルまでという制限があります。
Step 4:文字起こし用のプロンプトを入力する
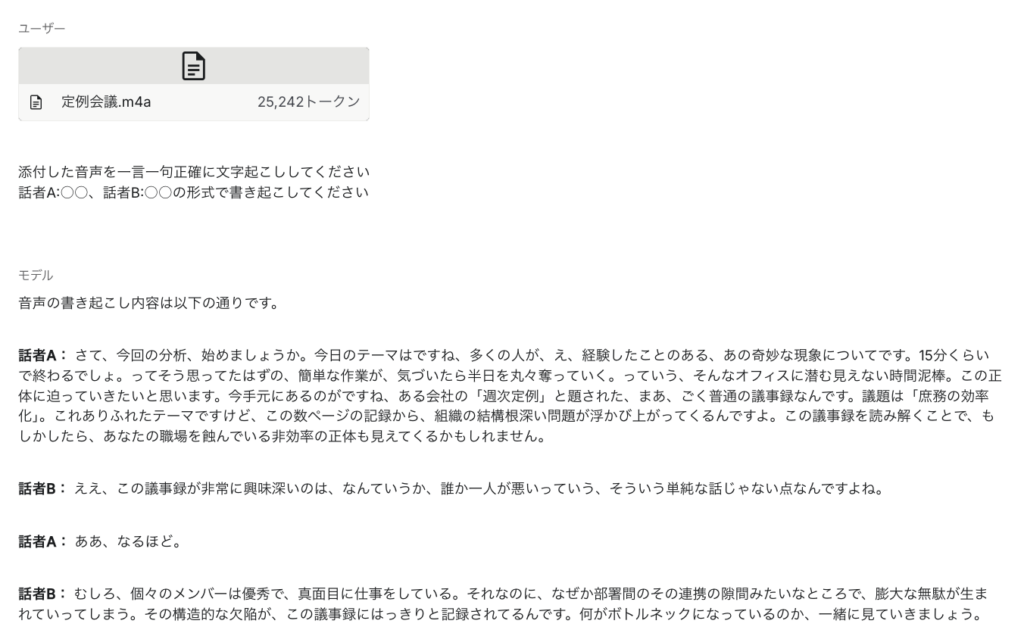
ファイルを読み込んだら、いよいよGeminiに文字起こしを依頼するプロンプトを入力します。
Google AI Studioのチャット入力欄に「添付した音声を一言一句正確に文字起こししてください」といった指示を書き込みましょう。
「えー」「あのー」などの不要なフィラーを除外したい場合は、その旨も伝えると良いですよ。
必要に応じて話者の区別やタイムスタンプの有無も指定すると、より使いやすい出力が得られます。
「話者A:○○、話者B:○○の形式で書き起こしてください」のように記載すれば、複数人の会話も判別できます。
プロンプトを書き終えたら送信してみましょう。
Step 5:出力された文字起こし結果を確認・整形する

Geminiから文字起こし結果のテキストが出力されたら、内容を確認して必要に応じて整形・修正します。
まずは明らかな変換ミスや聞き取り間違いがないか、元の音声と照らし合わせてチェックしましょう。
専門用語や人名の固有名詞などは誤字になりやすいため、事前に用意したメモを参照しながら正しく修正します。
生成されたテキストは、そのままでは口語表現が多く読みにくい場合もありますよ。
適宜、段落分けをしたり句読点を補ったりして読みやすい文章に整形しましょう。
こうして出来上がったテキストをコピーし、議事録テンプレートやドキュメントファイルに貼り付けて保存すれば完了です。
Geminiで文字起こしができない・止まる原因
便利なGeminiですが、場合によっては文字起こしがうまくできなかったり、処理が途中で止まってしまうこともあります。
この章では、Geminiで文字起こしを実行する際によくある失敗原因について解説しますね。
対応策と併せて原因を理解しておけば、エラー発生時にも慌てず対処できるでしょう。
対応していない音声・動画ファイル形式を使用している
Gemini(Google AI Studio)は読み込み可能なファイル形式が決まっています。
サポート外の形式のファイルをアップロードしても、音声を認識できず文字起こしを開始しません。
たとえば拡張子が特殊な音声コーデックやDRM付きのファイルは非対応です。
基本はMP3やWAV、MP4など一般的なフォーマットであれば問題ありませんよ。
念のため自分のファイル形式が対応リストに含まれているか事前に確認しましょう。
もし非対応であれば、無料の変換ツールなどで対応形式に変換してから再挑戦してください。
音声・動画ファイルの容量や長さが上限を超えている
アップロードするファイルサイズや音声の長さにも制限があります。
Google AI Studioでは1ファイルあたり最大2GB程度、音声で約9.5時間程度までが目安とされています。
これを超えるような超長時間の録音データを一度に処理しようとすると、途中でモデルが応答を止めてしまったりエラーになる可能性が高まりますよ。
特にGemini Flashモデルは一度に処理できる出力の長さに限界があり、あまりに長い文字起こし結果は途中で出力が途切れてしまうケースも報告されています。
そのような場合は、ファイルを複数に分割するか、重要な部分ごとに区切って順番に文字起こしすると良いでしょう。
また、一日に大量のリクエストを送信しすぎて使用量制限に達してしまった場合も新たな処理が止まります。
音声の品質が低く、認識が正常に行えない
録音の音質が悪い場合も文字起こしが滞る原因となります。
マイク性能が低かったり周囲の雑音が大きかったりすると、AIが音声を正確に聞き取れません。
結果、文章への変換精度が大きく低下したり、何も出力されなかったりする可能性があります。
対策としては、できるだけクリアな音声を用意することが重要ですよ。
ノイズリダクションのソフトで雑音を軽減したり、話者の声が小さい場合は音量を調整してからアップロードすると良いでしょう。
また、録音環境の見直し(周囲の静かな場所で録音する、マイクを音源に近づける等)も効果的です。
プロンプトの指示が不十分、または曖昧になっている
Geminiは与えられたプロンプトの内容に従って動作します。
そのため、指示が不十分だったり曖昧だったりすると、期待通りに文字起こしが行われない場合があります。
たとえば何も指示を出さずにファイルをアップロードしただけでは、Geminiは自発的に文字起こしを開始しません。
アップロード後に「文字起こししてください」と依頼する必要がありますよ。
また「要点をまとめて」などと曖昧に頼むと、AIが音声全体を聞かずに推測でまとめてしまい、逐語的な文字起こしにはなりません。
正確に一言一句起こしてほしい場合は、その旨をはっきりと伝えることが大切です。
Gemini(Google AI Studio)のモデル選択が適切でない
Google AI Studioでは複数のGeminiモデルが使えるため、用途に合ったモデルを選ぶ必要があります。
もしモデル選びが不適切だと、文字起こしがうまく進まないことがありますよ。
たとえば、テキスト生成に特化したモデルが選ばれていると、音声ファイルを入力しても処理できません。
また、Geminiには性能と速度が異なるPro版とFlash版が存在します。
Gemini Flashは高速ですが長時間音声の処理や複雑な内容で精度が劣る場合があり、逆にGemini Proは精度が高い反面一度に送信できる回数制限が厳しいです。
難しい専門用語が多い音声や多言語が混在する音声を文字起こしする際には、精度の高いProモデルの方が適しています。
ブラウザや通信環境の影響で処理が途中で止まる
Geminiの文字起こし処理中にブラウザの不具合やネットワーク問題が起こると、結果が最後まで取得できないことがあります。
たとえば処理中にブラウザタブを誤って閉じてしまったり、インターネット接続が途切れたりすると、せっかくの文字起こしが途中で中断されてしまいますよ。
特に長時間の音声を扱う際は、処理完了まで安定した回線を維持することが大切です。
また、PCのスペックやメモリ使用状況によってはブラウザが固まって応答しなくなるケースもあります。
その場合は一度ページをリロードして、再度アップロードから始めるのが無難です。
万一に備え、重要な文字起こし結果は都度コピーして別途保存しておくと安全でしょう。
無料利用枠の制限に達している
Google AI Studio上のGeminiは基本無料で使えますが、利用には一定の枠制限があります。
無料アカウントではモデルごとに1分あたりや1日あたりのリクエスト上限が決められており、これを超過すると一時的に使用が制限されます。
たとえばGemini Flashなら1分間に15回、1日あたり1500回まで、Gemini Proなら1分間に2回、1日50回までリクエスト可能ですよ。
長時間の音声を扱うとこの上限に達しやすく、上限超過時には新たな文字起こし要求が受け付けられなくなります。
このような制限に達した場合、一定時間待ってリセットされるのを待つか、日を改めて再度利用してください。
頻繁に大量の文字起こしが必要な場合は、将来的に使える有料プランやGoogle Cloudのサービスも検討すると良いでしょう。
Geminiで文字起こしをするときの活用事例
Geminiを活用すれば、いろいろなシーンで音声データを有効に使えます。
以下に、Geminiで文字起こしを行う具体的な活用事例を紹介しますね。
業務効率化から学習サポートまで、幅広い用途でのメリットを理解することで、あなたの状況に合わせた使い方のヒントになるでしょう。
会議・ミーティングの議事録を効率的に作成する
ビジネスシーンで最も代表的な活用例が、会議の議事録作成です。
会議中にメモを取る代わりに録音しておき、終了後にGeminiで文字起こしすれば、発言内容を漏れなくテキスト化できます。
短時間で正確に議事録が作成できるため、手作業に比べて大幅な時間短縮になりますよ。
生成された文字起こしを元に、重要な決定事項やアクションアイテムをまとめれば議事録の完成です。
特に長時間のミーティングでもGeminiなら効率よく処理できるので、参加者全員が議論に集中できるという副次的な効果も期待できます。
オンラインセミナー・ウェビナーの内容を文字データ化する
社内研修やウェビナー、公開セミナーなどのオンラインセミナーを録画・録音し、それをGeminiで文字起こしする活用例です。
セミナー内容をテキスト化しておけば、後で講演内容を復習したり、参加できなかった人に配布する資料としてまとめたりできます。
Geminiは長時間の講演でも対応可能なため、丸ごと1セミナー分の記録をテキスト化することもできますよ。
さらに、生成されたテキストをGeminiに要約させれば、セミナーのハイライトや要点だけを抜き出した資料を作ることも容易です。
これにより、長時間の動画を再生しなくても内容を素早く把握できるため、社内ナレッジ共有や研修資料の作成が効率化します。
インタビューや取材音声を記事原稿用に文字起こしする
記者の取材やライターのインタビュー録音を記事原稿に起こす用途でもGeminiは活躍します。
録音した対談やインタビュー音声をGeminiにかければ、対話形式のテキストが瞬時に得られますよ。
人力で書き起こすと膨大な時間がかかるインタビューも、AIならスピーディーです。
得られた文字起こしテキストを元に必要な部分を抜粋・編集すれば記事原稿を作成できます。
Geminiの文字起こしは口語調で出力されるため、ライターはそこから文章調に整えるだけで済み、表現に専念できる強みがあります。
複数人の座談会でも、話者ラベルを付けて書き起こせば誰の発言かが明確になるので、編集作業がしやすくなるでしょう。
YouTubeや動画コンテンツの音声をテキスト化する
YouTube動画や社内の動画コンテンツをテキスト化するのも便利な使い方です。
Google AI Studioでは動画ファイルの直接アップロードに対応しているほか、YouTubeのURLを指定して内容を取得することもできます。
たとえば製品紹介の動画から台本を起こしたり、教育系YouTube動画の内容を書き起こして資料化したりといった応用が可能ですよ。
Geminiは動画内の音声も精度高くテキスト化できるため、字幕ファイル(たとえばSRTファイル)の作成にも活用できます。
特に動画制作の現場では、音声から自動で文字起こしして台本や字幕にできれば作業効率が大きく向上します。
また、社内向けの録画資料などもテキストがあればキーワード検索ができるようになるため、情報の再利用性が高まります。
講義・勉強会の録音データを学習用テキストにする
大学の講義や勉強会・研修の録音を文字起こしし、学習ノートとして活用する方法です。
長時間にわたる講義内容もGeminiに任せれば漏れなく書き出せます。
後からノートを見返すようにテキストで内容確認できるため、聞き逃した部分の補完や理解の振り返りに役立ちますよ。
実際、学生がGeminiで講義を文字起こしノート化するケースも増えており、「授業やニュース動画を簡単に要約できる」と評価されています。
また、文字起こしテキストをさらにGeminiに要約させることで、重要なポイントだけを抜き出した学習資料を作ることも可能です。
勉強会の記録を全員に配布したり、共通のナレッジ蓄積として残す際にも、自動文字起こしは非常に便利な手段となります。
アイデア出しや音声メモを文章として整理する
スマホのボイスメモやICレコーダーに吹き込んだアイデア音声メモを、Geminiでテキスト化して整理する活用例です。
ひらめいたアイデアを音声で残しておき、後でGeminiに書き起こしてもらえば、テキストベースでアイデアを推敲したりまとめたりできます。
特に、移動中などキーボード入力できない状況で録音したメモも、Geminiがあれば後から手軽に文字に起こせますよ。
スマホで録音した短い音声メモのテキスト化はGeminiの得意分野で、音声を大量に打ち込むよりも正確かつスピーディーです。
出力されたテキストを箇条書きに整形したり、関連するアイデア同士を組み合わせることで、発想を広げたり整理したりする作業がはかどるでしょう。
音声から文章への変換を繰り返すことで、思考の整理と記録が効率よく行えます。
多言語音声を文字起こしして翻訳・要約に活用する
Geminiは多言語の音声にも対応しており、外国語の音声を文字起こしして活用することも可能です。
たとえば英語のプレゼン音声をGeminiで英文テキストに起こし、それをさらにGeminiに翻訳させて日本語の要約を得るといった使い方ができます。
複数の言語が混在する会議録音でも、それぞれを検出してテキスト化できるためグローバルな現場で重宝しますよ。
ただし、内容が高度で複数言語が混在する場合は小型モデル(Flash)では誤認識が増える傾向にあるため、精度重視でProモデルを使うのがおすすめです。
また、出来上がった文字起こしテキストを元にGeminiで要約・翻訳を行えば、国際会議の議事録を迅速に多言語展開するといった高度な活用も可能です。
言語の壁を越えて情報共有する上でも、Geminiの文字起こし機能は大いに役立つでしょう。
Geminiの文字起こしの精度を上げるプロンプトのコツ
Geminiでより高精度な文字起こし結果を得るには、プロンプト(AIへの指示文)の工夫が重要です。
ここでは、文字起こし専用の指示の出し方に関するポイントを紹介しますね。
ちょっとしたコツを押さえるだけで、認識精度が向上したりフォーマットの整ったテキストを得やすくなります。
文字起こし専用であることを最初に明示する
まずAIに対し「文字起こしを行うモード」であることを明示しましょう。
プロンプトの冒頭で「これから音声の文字起こしをお願いします」と宣言するイメージです。
こうすることで、Geminiは余計な創造的文章生成ではなく逐語的な書き起こしタスクに集中しやすくなりますよ。
具体的には、システムメッセージや最初の指示で「あなたは優秀な文字起こし士です。与えられた音声を正確にテキスト化してください。」のように役割を指定すると効果的です。
AIに役割を与えるプロンプト術はChatGPTなどでも知られていますが、Geminiでも同様に有効。
初手でモードを明示することが、高精度な文字起こしの第一歩となります。
話し言葉を省略せず、そのまま書き起こすよう指示する
発話内容を一字一句漏らさず書き起こすようプロンプトで指定しましょう。
Geminiは要約やリライトも得意なため、明示しないと省略や言い換えをしてしまう恐れがあります。
逐語的な文字起こしには「話し言葉をそのまま文字にしてください」「一言一句正確に起こしてください」という表現が効果的ですよ。
たとえば話者が「それで、まあ、その…実は」と言った場合も、きちんと「それで、まあ、その…実は」と間の取り方も含め書いて欲しいならそう指示します。
逆に「要点だけまとめて」などと書くと内容が省略されてしまうので注意が必要です。
Geminiにはあえて口語表現も省略しないようお願いし、元の喋りのニュアンスを保った出力を得ると良いでしょう。
不要な相づちやフィラーを除外する条件を指定する
話者の「ええと」「あのー」といった相づち・フィラー(埋め草言葉)は、文字起こし結果から除いた方が読みやすくなります。
Geminiに文字起こしを依頼する際、プロンプトで不要な語句を除外するルールを付与しましょう。
具体的には、「『あー』『うーん』など意味のない音や相づちはテキストに含めないでください」と指示しますよ。
こうすることで、AIは発話内容を忠実に書き起こしつつも、読みにくさの原因となる声のクセを取り除いてくれます。
ただし、話者が発した意味のある言葉まで消さないよう、曖昧な指示は避けましょう。
「無言の間のフィラーや関係ない笑い声は表記しないでください」といった具合に具体例を示すとより確実です。
話者を区別して出力するように指定する
複数人が会話している音声を文字起こしする際は、話者ラベルを付与して区別できるように指示しましょう。
「話者を区別してください」「Aさん、Bさんのように話者名をつけて書き起こしてください」などとプロンプトに書き加えます。
Geminiは音声の特徴から話者を見分ける能力も持っていますので、指示さえすれば自動的に話者交替を検出してラベルを振ってくれますよ。
たとえば会議音声なら「話者1」「話者2」、インタビューなら「インタビュアー」「回答者」といった形で出力させることも可能です。
実際のプロンプト例としては「登場人物:山田(インタビュアー)、佐藤(インタビュー対象)。これらの話者名を用いて書き起こしてください。」のように登場人物を明示すると良いでしょう。
そうすることで固有名詞の誤認識も防げ、後でテキストを読む際に誰が何を言ったかがひと目で分かるようになります。
専門用語や固有名詞を正確に表記するよう補足する
業界特有の専門用語や、人名・地名などの固有名詞はAIが聞き取れても誤った表記に変換してしまうことがあります。
そこで、プロンプト内であらかじめ重要な用語の正しいつづりや漢字を書き添えておくと効果的ですよ。
たとえば「専門用語:イノベーション、KPI」「登場人物名:田中太郎、Michael(マイケル)」のようにリストアップしてプロンプト末尾に付記します。
Geminiはこれらの情報を参照しながら文字起こしするため、聞き取りに自信がない単語でも候補から正しい表記を選んでくれる可能性が高まります。
特にカタカナ英語や略語、固有名詞の漢字は文脈だけでは難しい場合も多いので、事前にヒントを与えるイメージです。
こうした工夫で、最初から修正箇所の少ないクリーンな文字起こし結果を得られるでしょう。
タイムスタンプの有無を明確に指定する
文字起こし結果にタイムスタンプ(時間情報)を付けるかどうかもプロンプトで指定できます。
必要なら「各発言の前にタイムスタンプを付与してください(例:[00:05])」、不要なら「タイムスタンプは付けないでください」と明示しましょう。
タイムスタンプ付きの出力は、元の音声のどの時点の発言か後で照合できるメリットがありますよ。
議事録よりも字幕作成に近い用途や、長時間録音を部分的に参照したい場合に便利です。
一方で通常の議事録や文章として読む資料ではタイムスタンプは不要な場合も多いでしょう。
どちらにせよ、後から追加・削除する手間を省くために最初に方針を決めて伝えることが重要です。
文字起こし後の整形ルールをあらかじめ指定する
最終的に得られる文字起こしテキストの整形ルールも、プロンプトに組み込んでおくとスムーズです。
たとえば「一文ごとに改行してください」「箇条書きに整形してください」「発言者ごとに段落を分けてください」など、求めるフォーマットを先に伝える方法ですよ。
Geminiは指示に従って出力の体裁も整えてくれるため、後処理の手間を軽減できます。
実際の使い方として、「出力フォーマット:例)話者A:〇〇\n話者B:〇〇」というようにプロンプト内で簡易的な雛形を示す手もあります。
もちろん整形や要約と文字起こしを一度に指示しすぎると精度低下の恐れがあるため、状況に応じて段階を踏むことも大切です。
最初から完成形に近い形で文字起こし結果を得ることで、あとでコピペして資料にまとめる際なども作業が楽になります。
Geminiで文字起こしをするときの注意点
Geminiを使った文字起こしを安全かつ確実に行うために、事前に知っておくべき注意点があります。
便利な反面、AI特有の制約や取扱上の留意事項も存在しますよ。
ここでは、Geminiで文字起こしを活用する際に押さえておきたいポイントをまとめました。
Geminiは自動で文字起こしを開始するわけではない
まず誤解しやすい点として、Geminiはファイルをアップロードしただけでは自動では動作しません。
音声ファイルを投入した後、必ずユーザーが「この音声を文字起こしして」とプロンプトで指示を出す必要があります。
Google AI Studio上ではファイルを読み込んだだけでは何も起こらず、あくまでチャットボットに命令して初めて処理が始まる仕組みですよ。
初めて使う際に「ファイルを入れたのに何も返ってこない」と戸惑う人もいますが、プロンプトが未入力な場合はAIが待機している状態です。
また、一度に複数のタスクをさせる場合も一つずつ段階を踏む必要があります(文字起こし→要約→翻訳など)。
Geminiは万能ですが勝手に察して動くことはない点を覚えておいてください。
アップロードできる音声・動画ファイルの形式に制限がある
Geminiに投入可能なファイル形式には制限があります。
AI Studioでサポートされる音声はMP3やWAVなど主要な形式に限られ、動画もMP4やMOVなど一般的フォーマットのみ対応ですよ。
たとえばiPhoneのボイスメモ形式(m4a/AAC)や携帯電話独自の録音形式も基本的には扱えますが、極めてマイナーな形式や特殊コーデックはエラーになる可能性があります。
対応形式以外を使うとGemini側でデータを開けず、結果的に文字起こしができません。
また、高品質な可逆圧縮音源(たとえば96kHzのFLACなど)も処理負荷が高くなるため、一般的な44.1kHzや48kHzの16bit程度に変換しておくと良いでしょう。
アップロード前にファイル形式の確認を怠らないことで、不必要なトラブルを避けられます。
長時間音声は分割しないと失敗しやすい
Geminiは非常に長い音声にも対応可能ですが、それでも長時間音声を一度に処理すると失敗するリスクがあります。
モデルが扱えるトークン(文字数)の上限や、ブラウザ・サーバ側のタイムアウト制限などの影響で、2~3時間を超えるような音声は出力が途中で打ち切られることがありますよ。
特に無料版のGeminiでは、出力が長すぎると「続きを生成」ボタンを押さないとすべて表示されないケースも報告されています。
こういった場合は、録音を適切な長さ(30分~1時間程度など)ごとに分割して個別に文字起こしする方法が確実です。
その都度区切って処理すれば、仮に途中で止まってもどの部分まで完了したか分かりやすくなります。
Geminiの安定稼働のためにも、一件あたりの音声長は適度にコントロールすることが大事です。
音質が悪いと文字起こし精度が大きく低下する
AIによる文字起こしは音質に大きく左右されます。
録音状態が悪いと、人間には聞き取れてもAIにはノイズとして扱われてしまい、誤変換や文字抜けが増えてしまいますよ。
たとえば周囲の雑音が激しい環境音声や、マイクに雑音(ザザーッという風切り音等)が乗ったデータでは精度が落ちます。
対策として、できるだけクリアな音声を用意することが重要です。
雑音低減フィルターの使用や、簡易的でもいいのでノイズリダクション処理を事前にかけると効果があります。
Geminiで得られた文字起こし結果に不明瞭な箇所が多い時は、元音声の品質改善を検討してみてください。
専門用語や固有名詞は誤変換されやすい
AIは一般的な言葉には強いですが、専門用語や特殊な固有名詞は誤変換の温床になりがちです。
たとえば人名の漢字や業界特有の略語など、人間なら文脈で分かるものでもAIは近い音の別単語に置き換えてしまうことがありますよ。
Geminiは文脈理解に優れているとはいえ、やはり辞書に載っていない造語やマニアックな用語は間違いやすいと認識しておきましょう。
対策としてはプロンプトであらかじめ正しい表記を教えておく方法が効果的です。
それでも出力結果に誤字が紛れていないか、最終的なチェックは人間の目で行う必要があります。
特に固有名詞や数字、専門用語のスペルなどは念入りに校正しましょう。
文字起こし結果は必ず人の目で確認・修正が必要
どんなにGeminiの精度が高くても、完全に人手不要とはいきません。
出力された文字起こし結果は下書きだと考え、必ず元音声と付き合わせて確認・修正しましょう。
AIには聞き間違いもありますし、文脈上おかしな句読点の入れ方をすることもありますよ。
特に重要な会議記録やインタビュー記事では、誤字一つが意味を変えてしまう恐れもあるため慎重なチェックが必要です。
人間がゼロから書き起こすのに比べれば格段に負担は減りますが、最後の仕上げだけは人間が責任を持って行うようにしてください。
AIと人との協働で質の高い文字起こしを完成させましょう。
機密情報・個人情報を含む音声の取り扱いに注意する
Geminiに音声データをアップロードする際は、内容の機密性にも配慮が必要です。
AI Studioにアップロードしたデータは一時的にGoogleのサーバに送信され処理されます。
そのため、社外秘の会議や個人情報満載の録音を扱う際には情報漏えいリスクを認識しておかなければなりませんよ。
ユーザー企業のポリシーによってはクラウドAIへのデータ投入を禁止している場合もあります。
また、文字起こしした結果にも個人名やプライバシー情報が含まれるなら、その保管・共有方法にも注意しましょう。
さらに、著作権のある音声(市販の音声コンテンツや音楽ライブ音源など)を無断で文字起こしし公開することは法的にも問題となり得るので気をつけてください。
Geminiの文字起こしに関するよくある質問
Geminiでの文字起こしに関して多くの人が疑問に思う点をQ&A形式でまとめました。
リアルタイムで使えるのか、スマホでも可能か、無料枠の範囲など利用シーンに即した質問に回答していきます。
- Geminiでリアルタイム文字起こしは可能?
-
現時点ではGemini単体にリアルタイム文字起こし機能はありません。ただし、Googleドキュメントの音声入力でリアルタイムに文字起こしし、そのテキストをGeminiに貼り付けるという方法があります。また、Geminiのモバイルアプリ版には「Gemini Live」という機能があり、AIと直接対話する中でGeminiの応答がリアルタイム表示される仕組みもあります。
- スマホからGeminiで文字起こしはできる?
-
スマホのブラウザからでもGoogle AI Studioにアクセスすれば文字起こし可能です。ただし、長時間の音声ファイルを扱う際にはPCの方が安定して処理できる傾向があります。スマートフォンから音声ファイルをアップロードする場合は、Wi-Fiなど安定した通信環境を利用しましょう。
- Geminiでmp3・mp4を文字起こしすることはできる?
-
はい、GeminiはMP3音声ファイルやMP4動画ファイルの文字起こしに対応しています。Google AI Studio上でMP3などの音声ファイルをアップロードすれば、その内容をテキスト化できます。MP4形式の動画ファイルも直接読み込ませて音声部分を起こすことが可能です。
- iPhoneのボイスメモからGeminiで文字起こしするには?
-
iPhoneのボイスメモをGeminiで文字起こしするには、まずメモをファイルとして取り出してからアップロードします。ボイスメモアプリで録音した音声は通常m4a形式(AACコーデック)で保存されますが、GeminiはAACにも対応しているのでそのまま使えます。共有機能から自分宛てにメール送信するなどしてPCに転送し、AI Studioでアップロードしてください。
- Geminiの文字起こしは無料でどこまで使える?
-
Geminiの文字起こし機能は現状、無料枠内でかなり広範囲に利用できます。Google AI Studio上では基本料金不要で、長時間の音声でも約9時間程度までは一度に処理が可能とされています。ただし、モデルごとに1日あたりのリクエスト上限が決められており、たとえばGemini Proなら1日50回までです。
- Geminiの文字起こしに制限はある?
-
はい、いくつかの制限事項があります。一度に扱えるテキスト量(トークン数)に上限があるため、極端に長い音声は途中までしか文字起こしできません。また、対応ファイル形式やサイズの制限も存在します。無料版におけるリクエスト回数制限やレート制限もあり、一日に処理できる回数・頻度に上限が設けられています。
- Geminiの文字起こしに対応している音声・動画ファイルの形式は?
-
音声ファイルならMP3、WAV、FLAC、OGG、AACなど一般的なフォーマットが利用可能です。動画ファイルの場合はMP4、AVI、MOV、WebM、MPEG、WMV、3GPPといった主要形式に対応しています。YouTube動画についてはURL入力にも対応しているため、ファイルとして用意しなくてもリンク指定で文字起こし・要約が可能です。
まとめ:Geminiで文字起こしをして会議を効率的に
本記事では、Googleの生成AIモデルGeminiを使った文字起こしの方法から活用事例、精度向上のコツ、注意点まで幅広く解説しました。
従来は人手で時間をかけていた音声のテキスト化も、Geminiを使えば短時間で高精度に処理できます。
実際、Geminiを活用することで音声文字起こしの効率化が図れ、議事録作成や記事執筆に要する時間短縮や情報漏れの防止に役立ちます。
その結果、生まれた時間的余裕を内容のブラッシュアップや他の業務に充てることができ、生産性とアウトプット品質の向上につながるでしょう。
とはいえ、モデル選びやプロンプトの工夫、セキュリティ面への配慮など、注意すべき点もいくつかあります。
この記事で紹介した使い方やポイントを踏まえて、ぜひGeminiでの文字起こしを安全に活用し、日々の業務や学習の効率化に役立ててみてください。








