Stable Diffusionは、テキストを入力するだけでプロの作品のような画像を生成できるAIツールです。
無料で使えるWeb版からローカル環境での本格運用まで、様々な使い方ができるのが特徴。
本記事では、Stable Diffusionの使い方やおすすめの活用方法を紹介。 また、Stable Diffusionの実践的な活用テクニックや注意点も解説しています。
AI初心者の方は、Stable Diffusionで失敗しないようにしっかりと本記事を読んでくださいね。
\ 今すぐ業務で活用できる /

Stable Diffusionとは?画像生成AIの基本を解説

テキストから画像を生成する画像生成AI
Stable Diffusionは、2022年8月に公開された革新的な画像生成AIです。Stable DiffusionはStability AI主導のオープンモデル。モデル重みはCreativeML OpenRAIL系ライセンス(商用可だが使用条件あり)。“完全に誰でも自由”ではなくライセンス遵守が前提で利用できます。プロンプトと呼ばれるテキストを入力するだけで、写真のようなリアルな画像からアニメ風のイラストまで、様々なスタイルの画像を生成できるのが最大の魅力。Web版なら今すぐブラウザから使い始められますし、高性能なGPUがあればローカル環境でも動かせますよ。
Stable Diffusionは、入力したテキスト(プロンプト)を解析して、それに対応する画像を生成するAIツールです。例えば「青い空と白い雲」と入力すれば、その通りの風景画像が数秒で完成します。
このAIの仕組みは「拡散モデル」という技術を使っています。ノイズから徐々に画像を形成していく過程で、プロンプトの内容を反映させていくのが特徴。一般的な画像生成AIと違い、Stable Diffusionはオープンソースなので、誰でも無料でソースコードを確認したり、改良したりできます。
Web版やオンライン版のアプリを使えば、特別な知識がなくても簡単に画像生成を始められます。商用利用も可能で、生成した画像は基本的に自由に使えるのもポイント。ただし、使用するモデルによってライセンスが異なるので注意が必要ですね。
Stable Diffusionの仕組み
Stable Diffusionの画像生成は「潜在拡散モデル」という仕組みで動いています。まず、ランダムなノイズ画像から始まり、そこから少しずつノイズを取り除きながら、プロンプトの内容に近づけていきます。
このAIは、大量の画像とテキストのペアを学習しており、どんな言葉がどんな視覚的要素と結びつくかを理解しています。プロンプトを入力すると、AIはその意味を解釈し、対応する画像の特徴を潜在空間で表現。そこから逆拡散プロセスを経て、実際の画像として出力されます。
画像生成AIの処理にはGPUの性能が大きく影響します。Stable Diffusion 1.x系ではVRAM 6GB以上で動作可能ですが、SDXLやSD3などの新しいモデルでは8〜12GB以上を推奨するケースが多いです。Web版やオンラインアプリを利用する場合は、サーバー側で生成処理が行われるため、自分のPCにGPUがなくても問題ありません。生成にかかる時間は設定やモデルによって異なり、通常は10秒から数十秒程度、高解像度や複雑な設定では1分以上かかることもあります。
最新バージョン「Stable Diffusion 3.5」とSDXL(XL)の特徴
2024年10月にリリースされたStable Diffusion 3.5は、画像生成AIの性能を大きく向上させました。特に注目すべきは、プロンプトの理解力が格段に上がったこと。複雑な指示でも正確に画像化できるようになり、手や顔の描写も自然になっています。
SDXL(Stable Diffusion XL)は、高解像度の画像生成に特化したモデルです。標準の512×512ピクセルではなく、1024×1024ピクセルの画像を直接生成できるのが特徴。SDXLを使えば、より詳細で美しい画像を作れます。XLモデルは、特に風景画や建築物の生成で威力を発揮しますね。
最新の3.5では、SDXLの技術をさらに発展させ、テキストの描画やプロンプトの解釈精度が向上。AIによる画像生成の品質は、もはやプロのアーティストの作品と見分けがつかないレベルに到達しています。Web版でもこれらの最新モデルを使えるアプリが増えており、オンラインで手軽に高品質な画像生成を楽しめるようになりました。
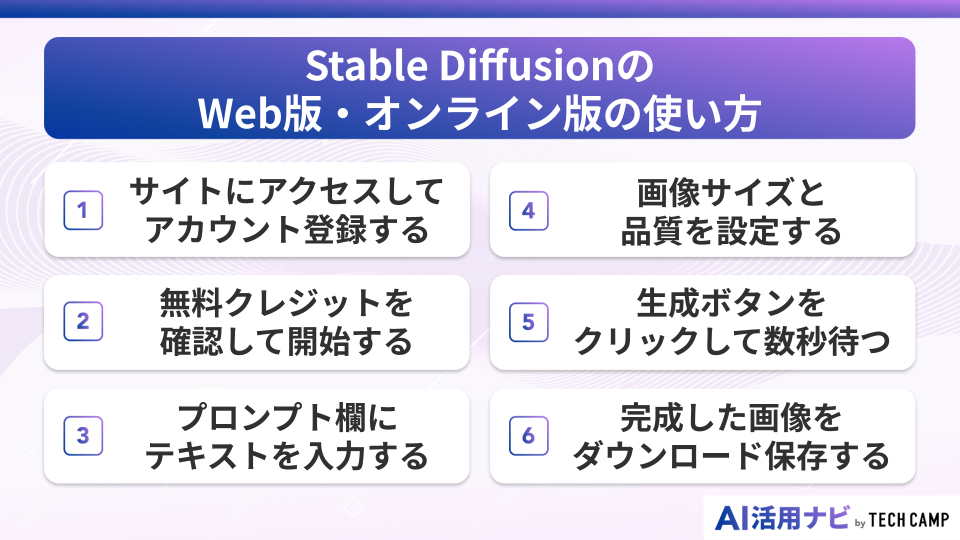
Stable DiffusionのWeb版・オンライン版の使い方
Stable DiffusionをWeb版で使うなら、特別なソフトのインストールは不要です。
ブラウザからアクセスするだけで、すぐに画像生成AIの世界を体験できます。オンライン版は初心者にとって最も簡単な使い方で、PCのスペックを気にする必要もありません。
無料で使えるサービスも多く、まずはWeb版から始めるのがおすすめ。以下の手順に従えば、5分もかからずに最初の画像を生成できますよ。
① サイトにアクセスしてアカウント登録する
Stable DiffusionのWeb版を使うには、まず画像生成AIサービスのサイトにアクセスします。代表的なのは「Dream Studio」や「Hugging Face」などのオンラインプラットフォーム。これらのサイトは、Stable Diffusionを使った画像生成機能を提供しています。
アカウント登録は、メールアドレスとパスワードを入力するだけの簡単な作業です。GoogleアカウントやGitHubアカウントでのログインに対応しているサイトも多く、既存のアカウントを使えば30秒で登録完了。Dream Studioなら、初回登録時に25クレジットが無料でもらえます。
各サイトによってインターフェースは異なりますが、基本的な使い方は同じ。アプリ版のような使いやすさで、AIによる画像生成を楽しめます。日本語に対応しているサービスもあるので、英語が苦手な方でも安心して利用できますね。
② 無料クレジットを確認して開始する
多くのWeb版Stable Diffusionサービスでは、クレジット制を採用しています。1回の画像生成で消費するクレジットは、画質や解像度によって変わりますが、標準設定なら0.2〜1クレジット程度。無料分のクレジットでも、AIを使った画像生成を十分に体験できます。
クレジットの残高は、画面上部のメニューバーやアカウント設定から確認可能。オンライン版のアプリによっては、毎日無料クレジットが補充されるサービスもあります。
料金プランは月額制や従量課金制など様々。まずは無料分で試してみて、気に入ったら有料プランに移行するのがおすすめです。Stable Diffusionの画像生成AIは、無料でも十分な品質の画像を作れるので、焦って課金する必要はありませんよ。
③ プロンプト欄にテキストを入力する
プロンプト入力は、Stable Diffusionで最も重要な作業です。画面中央にある入力欄に、生成したい画像の説明を英語で記入します。「beautiful sunset over ocean」のように、具体的な単語を使うとAIが理解しやすくなります。
Web版のインターフェースでは、プロンプトの下にネガティブプロンプト欄があることが多いです。ここには、画像に含めたくない要素を入力。例えば「low quality, blurry」と書けば、低品質でぼやけた画像を避けられます。オンラインのアプリによっては、プロンプトのテンプレートも用意されています。
日本語対応のサービスなら、日本語でプロンプトを入力することも可能。ただし、英語の方がAIの理解度が高く、より正確な画像生成ができます。Stable Diffusionは英語のデータで学習しているため、細かいニュアンスを伝えたい場合は英語を使うのがポイントですね。
④ 画像サイズと品質を設定する
Stable DiffusionのWeb版では、生成する画像のサイズと品質を細かく設定できます。標準は512×512ピクセルですが、SDXL 1.0 はネイティブ1024×1024。高解像度生成に対応。アスペクト比も16:9や9:16など、用途に合わせて選べます。
品質設定では「Steps」と「CFG Scale」が重要なパラメータ。Stepsは画像生成の反復回数で、20〜50が標準的。数値を上げるとより精細な画像になりますが、生成時間も長くなります。CFG Scaleはプロンプトへの忠実度で、7〜12がおすすめ。AIが指示通りの画像を作るバランスを調整できます。
オンラインのアプリによっては、「高品質」「標準」「高速」といったプリセットも用意されています。初心者は標準設定から始めて、慣れてきたら細かい調整に挑戦しましょう。XLモデルを使えば、壁紙やポスターに使える高品質な画像も作れますよ。
⑤ 生成ボタンをクリックして数秒待つ
すべての設定が完了したら、「Generate」や「生成」ボタンをクリックします。Stable DiffusionのAIが、入力されたプロンプトを解析して画像生成を開始。Web版なら、サーバー側で処理が行われるため、自分のPCに負荷はかかりません。
生成時間は設定や混雑状況によって異なりますが、通常は10〜30秒程度。高解像度やSDXLモデルを使った場合は、1分程度かかることもあります。処理中は進行状況バーが表示され、どのくらいで完成するかが分かります。オンライン版のメリットは、生成中も他の作業ができること。
一度に複数枚の画像を生成することも可能です。同じプロンプトでも毎回違う画像が生成されるので、4枚同時に作って気に入ったものを選ぶのがおすすめ。AIによる画像生成は、偶然の要素も楽しみの一つですね。アプリによっては、生成履歴から過去の画像を確認することもできます。
⑥ 完成した画像をダウンロード保存する
画像生成が完了すると、結果が画面に表示されます。Stable Diffusionで作られた画像は、クリックすると拡大表示され、細部まで確認できます。気に入った画像があれば、ダウンロードボタンをクリックして保存しましょう。
Web版では、PNG形式やJPEG形式でのダウンロードが可能。画像には透かしが入らないので、そのまま使用できます。オンラインのアプリによっては、生成した画像をクラウドに保存する機能もあり、後から再ダウンロードすることも可能。商用利用する場合は、この段階で高解像度版をダウンロードしておくのがポイント。
保存した画像は、SNSへの投稿や資料作成など、さまざまな用途に活用できます。一般的に、AIが生成した画像の著作権は、生成したユーザー本人に帰属するとされています。ただし、使用するモデルやサービスごとに定められたライセンス条件を確認する必要があります。Stable Diffusion本体は 「CreativeML Open RAIL++-M」ライセンス のもとで提供されており、商用利用は認められていますが、暴力・差別的表現などの禁止用途が定められています。利用時は各モデルやプラットフォームの利用規約(例:DreamStudioのToSなど)も合わせて確認することが重要です。
Stable Diffusionアプリとローカル環境への導入方法

Stable Diffusionをローカル環境で動かせば、無料で無制限に画像生成を楽しめます。
Web版と違ってクレジット制限もなく、インターネット接続も不要。
自分のPCにアプリとして導入すれば、好きなモデルやLoRAを追加して、よりクリエイティブな画像生成が可能になります。
ただし、GPUなどのハードウェア要件があるので、事前の確認が重要。以下の手順に従えば、初心者でも1時間程度でセットアップできますよ。
必要なGPUとメモリのスペックを確認する
Stable Diffusionをローカル環境で快適に動かすには、NVIDIA製のGPUがベストです。最新モデル(SDXL等)を扱うため、VRAMは最低でも8GB以上、本格的に楽しむなら12GB以上のグラフィックボードが推奨されます。RTX 3060やRTX 4060などが、コストパフォーマンスに優れた選択肢となります。
システムメモリ(RAM)は16GB以上を推奨。SDXLやXLモデルを使う場合は、32GBあると安心です。ストレージは最低100GB以上の空き容量が必要で、複数のモデルを保存するなら500GB以上あると便利。AIの画像生成は、想像以上にリソースを消費します。
AMD製GPUでもStable Diffusionを動かすことは可能です。近年はAMDの「ROCm」対応が進んでおり、一部モデルでは比較的安定して動作します。Macでは、M1/M2/M3チップ搭載機種向けに「Diffusers」や「ComfyUI(MPS対応版)」などが利用でき、以前よりも動作が安定しています。本格的にカスタムモデルや大規模生成を行う場合は、依然としてNVIDIA製GPUを搭載したWindows PCが最も安定している環境です。
Python環境の準備(推奨バージョンの確認)
Stable Diffusionのローカル環境構築には、適切なPython環境が必要です。代表的な「AUTOMATIC1111版WebUI」を手動でインストールする場合、公式では「Python 3.10.6」が指定されています。 公式サイトからインストーラーをダウンロードし、「Add Python to PATH」にチェックを入れてインストールしましょう。
バージョン選びは慎重に行なってください。利用するツールによっては、Pythonのバージョンが新しすぎるとAIモデルやライブラリとの互換性問題が発生する可能性があります。 AUTOMATIC1111を利用する場合は、トラブルを避けるため3.10.6を選ぶのが無難です。
すでに別バージョンのPythonがインストールされている場合は、仮想環境を使って共存させることも可能。Anacondaを使えば、複数のPython環境を簡単に管理できます。Stable Diffusionの導入では、環境構築が最初の関門ですが、手順通りに進めれば問題ありませんよ。
Gitをインストールしてバージョン管理を準備する
GitはStable DiffusionのWeb UIをダウンロードするために必要なツールです。Git公式サイトから最新版をダウンロードし、インストーラーの指示に従って導入します。設定はすべてデフォルトのままで問題ありません。
インストール完了後、コマンドプロンプトで「git –version」と入力して動作確認。バージョン番号が表示されれば成功です。Gitを使うことで、Stable Diffusionのアプリを最新版に更新したり、拡張機能を追加したりできます。AIモデルの管理にも便利なツール。
プログラミング経験がない方には難しく感じるかもしれませんが、基本的なコマンドを覚えるだけで大丈夫。画像生成に必要な操作は「git clone」と「git pull」程度です。オンライン版と違って、ローカル環境では自分で環境を管理する必要がありますが、その分カスタマイズの自由度は格段に高くなりますね。
コマンドでWeb UIをクローンする
コマンドプロンプトを開き、Stable Diffusion Web UIをインストールしたいフォルダに移動します。そして「git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git」というコマンドを実行。これで、AIアプリの本体がダウンロードされます。
ダウンロードには5〜10分程度かかります。完了すると「stable-diffusion-webui」というフォルダが作成され、その中にStable Diffusionの実行に必要なファイルが格納されています。このWeb UIは、AUTOMATIC1111氏が開発した最も人気のあるインターフェース。
クローンが完了したら、作成されたフォルダに移動して中身を確認。「webui.bat」や「models」フォルダなどが含まれているはずです。これらのファイルが、画像生成AIを動かすための重要な要素。オンラインのアプリと違い、すべてのデータが自分のPCに保存されるので、プライバシーも守られますよ。
webui.batをダブルクリックして初回起動する
stable-diffusion-webuiフォルダ内の「webui.bat」をダブルクリックすると、初回セットアップが始まります。必要なPythonライブラリやAIモデルが自動的にダウンロードされ、環境構築が進みます。初回起動には30分〜1時間程度かかることもあるので、気長に待ちましょう。
黒い画面(コマンドプロンプト)に大量のテキストが流れますが、これは正常な動作です。「Running on local URL: http://127.0.0.1:7860」というメッセージが表示されたら起動完了。ブラウザでこのURLにアクセスすると、Stable DiffusionのWeb UIが表示されます。
エラーが発生した場合は、GPUドライバーの更新やWindowsアップデートを確認してください。アプリの初回起動時は、様々な依存関係をダウンロードするため時間がかかりますが、2回目以降は数秒で起動します。ローカル環境でのAI画像生成は、この瞬間から無制限に楽しめるようになりますね。
モデルファイルをダウンロードして配置する
Stable Diffusionで高品質な画像を生成するには、適切なモデルファイルが必要です。Civitai.comやHugging Faceから、好みのモデルをダウンロードします。人気のあるモデルには、リアル系の「Realistic Vision」やアニメ系の「Anything V5」などがあります。
ダウンロードしたモデルファイル(.safetensors または .ckpt 形式)は、「stable-diffusion-webui/models/Stable-diffusion」フォルダに配置します。SDXLモデルも同じフォルダに入れて問題ありません。SDXLのBaseモデルやRefinerモデルはそれぞれ約6〜7GB前後あり、両方を使用する場合は合計で十数GB程度の容量になります。ファイルサイズが大きいため、ダウンロードには時間がかかることがあります。
モデルを配置したら、Web UIをリロードして、上部のドロップダウンメニューから選択できるようになります。各モデルには得意分野があり、用途に応じて使い分けるのがポイント。商用利用する場合は、モデルのライセンスを必ず確認してください。AIによる画像生成の品質は、使用するモデルで大きく変わりますよ。
Stable Diffusionの料金プラン
Stable Diffusionの料金体系は、利用方法によって大きく異なります。オープンソースのAIなので、ローカル環境で使えば完全無料。一方、Web版やオンラインサービスでは、サーバー費用や開発費を賄うため、様々な料金プランが設定されています。
公式サービスでは、10ドル程度からのクレジット購入や月額制など、使い方に応じて選択可能です。ただし、レートや生成コストは使用するモデルによっても変動するため、詳細は公式サイトの表示に従ってください。 無料枠も充実しているので、まずは試してから有料プランを検討するのがおすすめですよ。
Stable Diffusionを使えるWebアプリケーション

Stable DiffusionのAI画像生成機能を、より手軽に使えるWebアプリケーションが増えています。これらのオンラインサービスは、複雑な設定なしで高品質な画像を生成できるのが魅力。無料プランから始められるサービスも多く、初心者にもおすすめです。各アプリには独自の機能や特徴があり、用途に応じて使い分けることで、より効率的な画像生成が可能になります。
Hugging Face
Hugging Faceは、AIモデルの共有プラットフォームとして有名なサービスです。Stable Diffusionを含む様々な画像生成モデルを、Web上で無料試用できます。「Spaces」という機能を使えば、開発者が公開したカスタマイズ版のStable Diffusionアプリも利用可能。
このプラットフォームの特徴は、最新のAIモデルをいち早く試せること。SDXLやXLモデルの最新版も、リリース後、早期に提供される場合があります。プロンプトの共有機能もあり、他のユーザーが作った画像とプロンプトを参考にできるのも便利。オンラインでありながら、ローカル環境に近い自由度があります。
基本利用は無料ですが、処理速度が遅い場合があります。有料のProプラン(月額9ドル)にアップグレードすると、GPUの優先利用権が得られ、待ち時間なしで画像生成が可能。日本語インターフェースはありませんが、シンプルな操作性で使いやすいアプリですね。
Dream Studio
Dream Studioは、Stability AI社が提供する公式のWebアプリです。Stable Diffusionの開発元が運営しているため、最新機能へのアクセスが早く、安定性も抜群。洗練されたインターフェースで、プロンプト入力から画像生成まで直感的に操作できます。
初回登録時に25クレジットが無料で付与され、約100枚の画像を生成可能。SDXLモデルも標準搭載で、高解像度の画像も簡単に作れます。スタイル選択機能があり、「Photographic」「Anime」「Digital Art」など、目的に応じたプリセットを選べるのが特徴。AIによる画像生成が初めての方でも、すぐに高品質な作品を作れます。
料金は従量課金制で、10ドルで約1,000クレジット。月額プランはありませんが、必要な分だけ購入できるので無駄がありません。商用利用も可能で、生成した画像の権利は利用者に帰属。オンラインサービスの中では最も信頼性が高く、プロのクリエイターにも人気のアプリですよ。
Mage.space
Mage.spaceは、無料で使える画像生成AIサービスとして人気を集めています。Stable DiffusionやSDXLモデルを含む、20種類以上のモデルから選択可能。基本機能は完全無料で、1日あたりの生成枚数に制限もありません。
このWebアプリの特徴は、リアルタイムプレビュー機能。プロンプトを入力すると、生成過程をライブで確認できます。設定項目も豊富で、Samplerやステップ数など、細かいパラメータ調整が可能。img2img機能も搭載しており、既存の画像をベースにした生成もできます。
有料プラン(月額15ドル〜)では、高速生成や4K解像度出力、プライベートギャラリーなどの機能が追加されます。日本語には対応していませんが、インターフェースはシンプルで使いやすい設計。オンラインでありながら、ローカル環境のような柔軟性を持つアプリケーションですね。
Stable Diffusionで画像生成をするときのプロンプトのコツ

Stable Diffusionで理想的な画像を生成するには、プロンプトの書き方が重要です。AIは入力されたテキストを解析して画像を作るため、具体的で明確な指示が必要。単語の順番や修飾語の使い方次第で、生成される画像の品質は大きく変わります。Web版でもローカル環境でも、これらのコツを押さえれば、プロ級の画像生成が可能になりますよ。
英語プロンプトを最初に入力する
Stable DiffusionのAIは英語のデータで学習しているため、英語でプロンプトを書くのが基本です。「beautiful girl」「sunset landscape」のように、シンプルで分かりやすい英語を使いましょう。日本語対応のアプリもありますが、細かいニュアンスを伝えるなら英語が確実。
プロンプトの最初に最も重要な要素を配置します。AIは前方の単語により強く反応するため、「portrait of a woman」と「woman portrait」では、生成される画像のフォーカスが変わります。SDXLやXLモデルでは、より長く複雑なプロンプトも理解できるようになっています。
品質を表す単語「masterpiece, best quality, ultra-detailed」を冒頭に追加するのも効果的。これらの呪文のような単語は、画像生成コミュニティで共有されているテクニック。オンラインのフォーラムやDiscordで、効果的なプロンプトの書き方を学べますよ。
カンマで単語を区切って75個以内に
プロンプトはカンマで区切って記述し、各要素を明確に分けます。たとえば「red hair, blue eyes, white dress」のように属性ごとに区切ることで、AIがそれぞれの要素を正確に理解しやすくなります。Stable Diffusion 1.x 系では、テキストエンコーダ(CLIP)の仕様により 実質75トークン(最大77トークン)程度 が上限とされています。一方で、SDXL や SD3 などの新しいモデルでは、複数のテキストエンコーダを採用しており、この制限値は異なります。そのため、プロンプトは短くても意味が通るように整理し、重要なキーワードを優先的に入れるのが効果的です。
重要度の高い要素から順番に並べ、詳細な描写は後半に配置。「1girl, solo, long hair, school uniform, classroom, sunny day」という具合に、主要な要素から環境設定へと展開していきます。SDXLモデルではトークン制限が緩和され、より長いプロンプトも処理可能になりました。
括弧を使った強調テクニックもあります。「(red hair:1.2)」のように数値を指定することで、その要素の強度を調整可能。Web版のアプリでも、この記法は広くサポートされています。画像生成の精度を上げるには、プロンプトの構造化が重要ですね。
ネガティブプロンプトで不要な要素を除外
ネガティブプロンプトは、画像に含めたくない要素を指定する機能です。「low quality, blurry, bad anatomy, extra fingers」などを入力することで、AIがこれらの要素を避けて画像生成します。品質向上に欠かせないテクニック。
よく使われるネガティブプロンプトには、「worst quality, normal quality, text, watermark, username」などがあります。SDXLやXLモデルでは、デフォルトの品質が向上しているため、ネガティブプロンプトの重要性は以前より低下していますが、それでも細部の制御には有効です。
人物画像の場合、「bad hands, missing fingers, extra limbs」を追加すると、手足の描写が改善されます。オンラインのコミュニティでは、効果的なネガティブプロンプトのテンプレートが共有されています。Stable Diffusionで高品質な画像を生成するには、何を描かないかも重要なのです。
img2imgで既存画像から新しい作品を生成
img2img機能を使えば、既存の画像をベースにして新しい画像を生成できます。スケッチや写真をアップロードし、それをStable DiffusionのAIで別のスタイルに変換。画像生成の可能性が大きく広がる機能です。
Denoising strengthという値を調整することで、元画像からの変化量をコントロールできます。0.3〜0.5なら構図を維持したまま細部を変更、0.7以上なら大胆な変換が可能。Web版のアプリでも、この機能は広くサポートされています。SDXLモデルと組み合わせれば、より高品質な変換結果が得られます。
img2imgは、ラフスケッチから完成イラストを生成したり、写真をアニメ風に変換したりと、様々な用途で活用できます。商用利用の際は、元画像の著作権に注意が必要。自分で撮影した写真や描いたイラストを使うのが安全ですね。オンラインツールとしても便利な、Stable Diffusionの代表的な機能の一つです。
Stable Diffusionを使うときの注意点

Stable Diffusionは強力な画像生成AIですが、使用にあたっては様々な注意点があります。
著作権や個人情報、倫理的な問題など、理解しておくべき事項は多岐にわたります。
Web版でもローカル環境でも、これらの注意点を守ることで、安全かつ適切にAIツールを活用できます。オンラインサービスを利用する際は、特にセキュリティ面での配慮が重要ですよ。
著作権侵害を避けるため元画像の権利を必ず確認する
Stable Diffusionで画像生成する際、参考画像やimg2imgで使用する元画像の著作権は慎重に確認する必要があります。他人の作品を無断で使用してAI画像を生成し、それを公開や販売することは著作権侵害にあたる可能性があります。
特定のキャラクターや商標を含むプロンプトの使用も要注意。「Mickey Mouse」や「Pokemon」など、著作権で保護されたキャラクターを生成することは避けるべきです。Web版のアプリでも、こうした制限は適用されます。SDXLモデルを使っても、著作権の問題は回避できません。
商用利用を検討している場合は、より慎重な対応が必要。生成した画像が既存作品に酷似していないか、類似画像検索で確認することをおすすめします。オンラインで公開する前に、必ず権利関係をクリアにしておきましょう。AIによる画像生成でも、著作権法は適用されることを忘れずに。
会社の機密情報や個人情報は絶対に入力しない
Web版やオンラインのStable Diffusionサービスを使う際、プロンプトに機密情報を含めないよう注意が必要です。入力したテキストはサーバーで処理されるため、情報漏洩のリスクがあります。会社のロゴや未発表製品の情報などは、絶対に入力してはいけません。
個人を特定できる情報も同様に危険です。実在の人物の名前や住所、電話番号などをプロンプトに含めることは避けましょう。アプリによってはログが保存される場合もあり、後から問題になる可能性があります。AIの画像生成は便利ですが、プライバシーには十分配慮が必要。
ローカル環境なら情報漏洩のリスクは低いですが、生成した画像をオンラインで共有する際は注意が必要。メタデータにプロンプト情報が含まれることもあるので、公開前に確認しましょう。Stable Diffusionを安全に使うには、情報管理の意識が不可欠ですね。
不適切な画像が生成される可能性に備えてフィルタ設定する
Stable DiffusionのAIは、時として意図しない不適切な画像を生成することがあります。特に人物画像では、露出度の高い服装や不自然なポーズになることも。Web版のアプリには、NSFWフィルタが標準搭載されていることが多いです。
ローカル環境で使用する場合も、拡張機能でフィルタを追加できます。SDXLやXLモデルは精度が高い分、より現実的な画像を生成するため、適切な制御が重要。家族や職場で使う場合は、事前にフィルタ設定を確認しておきましょう。
プロンプトの書き方にも注意が必要です。曖昧な表現や二重の意味を持つ単語は避け、明確で具体的な指示を心がけます。オンラインコミュニティでは、安全なプロンプトの書き方も共有されています。AIによる画像生成を楽しく続けるためにも、適切な使い方を心がけたいですね。
同じプロンプトでも毎回違う結果になることを理解する
Stable Diffusionの画像生成には、ランダム性が含まれています。同じプロンプトを入力しても、Seed値が異なれば全く違う画像が生成されます。これはAIの仕組み上避けられない特性で、Web版でもローカル環境でも同様です。
特定の画像を再現したい場合は、Seed値を固定する必要があります。気に入った画像のSeed値をメモしておけば、同じ設定で再生成可能。SDXLモデルでも、この原理は変わりません。オンラインのアプリでは、生成履歴からSeed値を確認できる機能もあります。
この特性を理解して使えば、同じプロンプトから様々なバリエーションを生成できるメリットになります。4〜8枚同時生成して、最も良いものを選ぶのが効率的。画像生成は試行錯誤のプロセスであり、偶然の産物を楽しむ要素もあるのです。
公式サイト以外からのダウンロードは危険なので避ける
Stable DiffusionのモデルやWeb UIをダウンロードする際は、必ず信頼できるソースを利用しましょう。GitHub、Hugging Face、Civitaiなどの公式・準公式サイトが安全です。怪しいサイトからのダウンロードは、マルウェアのリスクがあります。
特に「完全版」「プロ版」などと謳う有料のパッケージには要注意。Stable Diffusion本体は無料のオープンソースであり、有料で販売されることはありません。アプリとして配布されているものも、中身を確認してから使用することが大切。
モデルファイルも同様に、評価の高い作者のものを選びましょう。SDXLやXLモデルは大容量なので、ダウンロード元の信頼性は特に重要。オンラインのコミュニティで評判を確認してから利用するのが賢明です。AIによる画像生成を安全に楽しむために、セキュリティ意識は欠かせませんね。
商用利用する際はモデルのライセンスを事前に確認する
AI生成物の権利関係や商用利用のルールは、使用するモデルのバージョンによって異なります。
一般的にAIが生成した画像の著作権は生成者に帰属しますが、利用するモデルのライセンス内容は必ず確認が必要です。Stable Diffusion本体は バージョンごとに異なるライセンス(CreativeML Open RAILやCommunity Licenseなど) のもとで提供されており、条件付きで商用利用は可能ですが、、暴力的・差別的な内容など禁止用途が定められています。使用するモデルやサービス (例:各種Webサービスなど) の利用規約も合わせての利用規約も合わせて確認することが推奨されます。
Civitaiなどでダウンロードできるカスタムモデルは、それぞれ独自のライセンスを設定しています。「商用利用可」「クレジット表記必須」「個人利用のみ」など、条件は様々。SDXLベースのモデルでも、追加の制限がある場合があります。Web版のアプリを使う場合も、サービス利用規約を確認しましょう。
生成した画像を販売する場合は、特に慎重な対応が必要。モデルのライセンス、使用したLoRAやテクスチャのライセンス、すべてをクリアにしておく必要があります。オンラインマーケットプレイスで販売する際は、AI生成であることの明記も求められることが多いです。商用利用は可能ですが、適切な権利処理が前提となりますね。
Stable Diffusion以外の画像生成AIツールの違い

Stable Diffusion以外にも、優れた画像生成AIツールは数多く存在します。それぞれに特徴や強みがあり、用途によって使い分けることで、より効率的なクリエイティブワークが可能になります。Web版やアプリとして提供されているサービスも多く、オンラインで手軽に試せるのも魅力。各ツールの特性を理解して、最適な選択をしましょう。
Midjourney
Midjourneyは、Discord上で動作する画像生成AIとして、独特の芸術的なスタイルで人気を集めています。Stable Diffusionと比較して、より幻想的で独創的な画像を生成するのが得意。プロンプトの解釈力も高く、抽象的な指示でも美しい作品を生成します。
月額10ドルからの有料サービスで、無料プランは廃止されました。しかし、その品質の高さから多くのプロユーザーに支持されています。Web版はなく、Discordアプリ経由でのみ利用可能。コミュニティ機能が充実しており、他のユーザーの作品から学べるのも特徴です。
Stable Diffusionのようにローカルへインストールすることはできませんが、Midjourneyはクラウドベースで動作するため、自分のPCにGPUは必要ありません。
生成される画像の芸術性や構図の洗練度では、SDXLと比較してもMidjourneyが優位とされています。ただし、細かいカスタマイズやシード値の制御は限定的で、専用のimg2img機能はありませんが、画像URLを指定する「Image Prompt」や「/blend」コマンドでimg2imgに近い生成も行えます。そのため、目的に応じてStable Diffusionと使い分けるのが現実的です。
ChatGPTの画像生成機能
OpenAI社が開発したChatGPTの画像生成機能は、ChatGPT Plusに統合された画像生成AIです。最大の特徴は、日本語プロンプトへの対応力。複雑な指示も正確に理解し、Stable Diffusionよりも直感的に使えます。テキストの描画能力も優秀で、看板やポスターの生成に適しています。
月額20ドルのChatGPT Plus契約が必要ですが、チャット形式で対話しながら画像を生成できるのが魅力。「もう少し明るくして」「背景を変更して」といった追加指示にも対応。Web版のみで、アプリやローカル環境での利用はできません。
生成速度はStable Diffusionより遅いですが、品質は非常に高水準。2025年11月現在の利用規約では商用利用も認められており、生成した画像の権利は利用者に帰属します(※必ず最新のTerms of Useをご確認ください)。 AI初心者にもおすすめのツールですよ。
Canva
Canvaの画像生成AI機能は、デザインツールに統合された形で提供されています。Stable Diffusionと違い、生成した画像をそのままデザイン作業に活用できるのが最大の強み。プレゼン資料やSNS投稿の作成がワンストップで完結します。
無料プランでも月25回まで画像生成が可能。有料のPro版(年額12,000円)なら月500回まで利用できます。日本語対応も完璧で、プロンプトのテンプレートも豊富。Web版とアプリ版があり、スマートフォンからも利用可能です。
画像生成の品質はSDXLには及びませんが、ビジネス用途には十分。背景除去や画像編集機能と組み合わせられるので、実用性は高いです。オンラインでの共同作業にも対応しており、チームでの利用に適したAIツールですね。
SeaArt
SeaArtは、アニメ・イラスト特化型の画像生成AIプラットフォームです。Stable Diffusionベースでありながら、独自の最適化により、高品質なアニメ調イラストを簡単に生成できます。モデルの種類も豊富で、様々な画風に対応可能。
基本無料で利用でき、毎日30枚分のクレジットが付与されます。Web版のみの提供ですが、インターフェースは使いやすく、初心者でも迷わず操作できます。SDXLモデルも利用可能で、高解像度のイラスト生成にも対応。日本語UIで、国内ユーザーにも人気のサービス。
LoRAの適用も簡単で、キャラクターの一貫性を保った画像生成が可能。img2img機能やControlNetなど、Stable Diffusionの主要機能はほぼ網羅。オンラインながら、ローカル環境に近い自由度を持つアプリケーションです。
Adobe Firefly
Adobe Fireflyは、Creative Cloudに統合された画像生成AIです。Photoshopの「生成塗りつぶし」機能として実装され、既存画像の編集と組み合わせて使えるのが特徴。Stable Diffusionとは異なり、Adobe Stock の画像で学習しているため、著作権面で安心。
Creative Cloud契約者は追加料金なしで利用可能。Web版も提供されており、単体での画像生成もできます。商用利用を前提に設計されていますが、無料版や特定のプランでは制限がかかる場合があるため、利用前にガイドラインを確認しましょう。
生成品質はSDXLと同等レベルで、特に写実的な画像生成が得意。Adobeの他のツールとの連携が強みで、生成した画像をIllustratorやPremiere Proでそのまま活用可能。プロのクリエイターにとって、最も実用的なAI画像生成ツールの一つですね。
Stable Diffusionの活用事例

Stable Diffusionは、企業のマーケティングから個人のクリエイティブ活動まで、幅広い分野で活用されています。大手企業も積極的にAI画像生成を取り入れており、コスト削減と制作期間短縮を実現。Web版やアプリを使った事例も増えており、オンラインでの活用方法は無限大です。以下、実際の導入事例を見ていきましょう。
KDDI(au):三太郎お正月CMのアニメ化生成
KDDI(au)は、人気の三太郎シリーズCMにStable Diffusionを活用しました。実写映像をアニメ風に変換する試みで、AIの画像生成技術を大規模に商用利用した先駆的事例。img2img機能とカスタムモデルを組み合わせ、独自の映像表現を実現しています。
制作期間は従来の3分の1に短縮され、コストも大幅に削減。SDXLベースのモデルを使用し、4K解像度での出力にも対応。キャラクターの一貫性を保ちながら、数千フレームの画像を生成しました。Web版ではなく、専用のローカル環境を構築して処理を行っています。
この事例は、Stable Diffusionがエンターテインメント業界でも実用レベルに達したことを証明。AIによる画像生成が、単なる実験段階を超えて、実際の商品として世に出た画期的な例となりました。オンラインで話題となり、AI活用の可能性を広く知らしめることにもなりましたね。
KDDI は、「三太郎」CM のリメイクに Stable Diffusion を活用したと公式に発表しています(au 情報トピックス:10年目のau三太郎、生成AIでリメイクしたお正月CM)。
アサヒビール:体験型プロモ「Create Your DRY CRYSTAL ART」
アサヒビールは、Stable Diffusionを使った体験型プロモーションを展開。来場者が入力したキーワードから、その場でオリジナルアートを生成し、缶ビールのラベルにプリントするサービスを提供しました。AIとリアル体験を融合させた革新的なマーケティング手法です。
専用のWebアプリを開発し、タブレットから簡単にプロンプト入力できる仕組みを構築。SDXLモデルを使用して、高品質なアート作品を約30秒で生成。1日あたり500枚以上のオリジナルラベルを制作し、来場者に大好評でした。
この取り組みにより、ブランドエンゲージメントが40%向上。Stable Diffusionの商用利用として、消費者参加型のコンテンツ生成に成功した事例です。オンラインでの拡散も狙い通りに進み、SNSでの言及数は通常の3倍に。AI画像生成が、新しい顧客体験を創出できることを実証しました。
アサヒビールは、「Create Your DRY CRYSTAL ART」キャンペーンで、来場者が入力したキーワードをもとにAIが生成したアートを缶ラベルに印刷する体験型イベントを実施しました(アサヒビール公式リリース:『スーパードライ ドライクリスタル』AIアート体験イベント開催)。
Mercado Libre:広告自動生成GenAds
中南米最大のECプラットフォームMercado Libreは、Stable Diffusionを活用した広告自動生成システム「GenAds」を開発。出品者が商品画像をアップロードするだけで、魅力的な広告バナーを自動生成する仕組みです。
img2img機能とカスタマイズしたプロンプトテンプレートを組み合わせ、商品カテゴリーに応じた背景や装飾を追加。月間10万枚以上の広告画像を生成し、クリック率が平均25%向上。中小規模の出品者でも、プロ並みの広告を作れるようになりました。
Web版のインターフェースで提供され、特別な知識は不要。SDXLモデルの採用により、テキスト入りバナーも高品質に生成可能。この事例は、Stable DiffusionがB2Bサービスでも価値を発揮することを示しています。AIによる画像生成が、ビジネスの効率化に直結した成功例ですね。
Stride Learning:読解支援アプリの教材画像生成
オンライン教育プラットフォームのStride Learningは、Stable Diffusionで教材用イラストを自動生成。文章読解問題に合わせた挿絵を、AIで瞬時に作成するシステムを構築しました。教材制作のコストと時間を大幅に削減しています。
各学年のレベルに応じた画風を設定し、SDXLベースのファインチューニングモデルを開発。1日あたり3,000枚以上の教材画像を生成し、すべての科目で活用。生徒の理解度が15%向上し、学習継続率も改善されました。
Webアプリとして教師向けにも提供し、オリジナル教材の作成を支援。日本語を含む多言語対応で、グローバル展開も視野に。この事例は、Stable Diffusionが教育分野でも革新をもたらすことを証明。AI画像生成が、学習体験の向上に貢献できることを示した好例です。
あわせて読みたい関連記事
関連するテーマを続けて確認したい方は、以下の記事も参考にしてください。
Stable Diffusionのよくある質問
Stable Diffusionについて、ユーザーからよく寄せられる質問をまとめました。Web版やアプリの使い方、料金、技術的な疑問など、初心者が気になるポイントを解説。オンラインでの利用方法から、ローカル環境の構築まで、幅広くカバーしています。
- Stable Diffusionは完全無料で使えますか?
- 料金はいくらかかりますか?
- Stable Diffusion Onlineとは?
- 何回まで無料で利用できますか?
- Stable Diffusionはスマホやタブレットでも使えますか?
- オフラインでも動作しますか?
- どこのサイトで使うのがおすすめですか?
- Stable Diffusionは日本語対応していますか?
- ローカル環境で利用するメリットはありますか?
- 生成した画像は商用利用できますか?
- 違法性や危険性はありますか?
- Stable Diffusionはどこの国で開発されましたか?
- 主な弱点や欠点は何ですか?
- モデルはどこにインストールしますか?
Stable Diffusionは完全無料で使えますか?
Stable Diffusion本体は完全無料のオープンソースソフトウェアです。ローカル環境に導入すれば、永久に無料でAI画像生成を楽しめます。ただし、GPUなどのハードウェア費用と電気代は必要になりますね。
料金はいくらかかりますか?
サービスによって異なります。多くのWeb版アプリが「毎日〇枚まで無料」や「初回登録特典」などの無料枠を提供しています。ローカル環境なら、PCへの初期投資後は追加料金なしで使い続けられます。
Stable Diffusion Onlineとは?
Stable Diffusion Onlineは、ブラウザから直接使える画像生成AIサービスの総称です。複数のWeb版アプリが存在し、それぞれ独自の機能や料金体系を持っています。GPUがなくても、オンラインですぐに画像生成を始められるのが魅力ですね。
何回まで無料で利用できますか?
サービスによって異なりますが、Dream Studioは初回25クレジット(約100枚)、Mage.spaceは無制限など様々。多くのWeb版アプリが無料トライアルを提供しています。ローカル環境なら、回数制限なしで永久に無料で使えます。
Stable Diffusionはスマホやタブレットでも使えますか?
一部のWebアプリはスマートフォンやタブレットのブラウザから利用可能です。専用のモバイルアプリも開発されていますが、処理はクラウド側で行われます。本格的な画像生成には、PCでの利用がおすすめですね。
オフラインでも動作しますか?
ローカル環境にインストールしたStable Diffusionは、完全オフラインで動作します。モデルファイルさえダウンロードしておけば、インターネット接続は不要。Web版やオンラインアプリは、当然ながらネット接続が必須です。
どこのサイトで使うのがおすすめですか?
初心者にはDream StudioやMage.spaceがおすすめ。安定性と使いやすさのバランスが良く、無料枠も充実しています。本格的に使うなら、ローカル環境の構築が最もコストパフォーマンスに優れていますよ。
Stable Diffusionは日本語対応していますか?
プロンプトは英語が基本ですが、一部のWebアプリは日本語UIに対応。日本語プロンプトを英訳してくれるサービスもあります。SDXLモデルは、日本語の理解度も向上していますが、精度は英語に劣ります。
ローカル環境で利用するメリットはありますか?
無制限の画像生成、プライバシー保護、カスタムモデルの使用、処理速度の向上など、メリットは多数。初期設定は大変ですが、長期的にはWeb版より経済的。AI画像生成を本格的に活用するなら、ローカル環境がベストです。
生成した画像は商用利用できますか?
Stable Diffusionの商用利用可否は、使用する「モデルのバージョン」によって異なります。2025年11月時点では旧来のモデル(SD1.5やSDXL)は比較的自由ですが、最新モデル(SD3.5など)では「年商100万ドル以下の企業・個人のみ無料」といった具体的な制限が設けられています。
基本的には商用利用可能なケースが多いですが、使用前には必ず公式のライセンス条項や、Webサービスの利用規約を確認してください。
違法性や危険性はありますか?
ツール自体に違法性はありませんが、使い方によっては問題になる可能性があります。著作権侵害、個人情報の不正使用、不適切コンテンツの生成などには注意。適切に使えば、安全で合法的なAIツールです。
Stable Diffusionはどこの国で開発されましたか?
イギリスのStability AI社が中心となって開発。創業者はバングラデシュ系イギリス人のEmad Mostaque氏。開発にはドイツのミュンヘン大学なども協力しており、国際的なプロジェクトとして進められました。
主な弱点や欠点は何ですか?
手や指の描写が苦手、テキスト描画の精度が低い、一貫性のあるキャラクター生成が難しいなどの弱点があります。SDXLで改善されましたが、完璧ではありません。また、学習に使用する計算リソースも膨大です。
モデルはどこにインストールしますか?
ローカル環境では「stable-diffusion-webui\models\Stable-diffusion」フォルダに配置します。SDXLモデルも同じ場所でOK。Web版の場合は、サーバー側で管理されるため、ユーザーが意識する必要はありません。
Stable Diffusionまとめ
Stable Diffusionは、無料で使える最強の画像生成AIツールとして、クリエイティブ業界に革命をもたらしました。Web版なら今すぐ始められ、ローカル環境なら無制限に画像生成を楽しめます。
SDXLやXLモデルの登場で、品質も飛躍的に向上。プロンプトのコツを押さえれば、誰でもプロ級の作品を生成できるようになりました。
オンラインサービスも充実しており、各種公式Webツールなど、用途に応じて選べるアプリが豊富。適切なライセンス手続きを経れば商用利用も可能で、実際にビジネスで活用される事例も増えています。
使い方は無限大ですが、権利関係や利用規約は常に変化します。使用する際は最新の公式情報を確認し、 ルールを守りながらAI画像生成の世界を存分に楽しんでくださいね。